说明
在正式进行部署之前先了解下关于Kubernetes的几个核心知识点
Kubernetes是什么
Kubernetes是Google在2014年开源的一个容器集群管理系统,Kubernetes简称K8S。
Kubernetes用于容器化应用程序的部署、扩展和管理
Kubernetes提供了容器编排,资源调度,弹性伸缩,部署管理,服务发现等一系列功能。
Kubernetes目标是让部署容器化应用简单高效
Kubernetes特性 在节点故障时重新启动失败的容器,替换和重新部署,保证预期的副本数量;杀死健康检查失败的容器,并且在未准备好之前不会处理客户端请求,确保上线服务不中断。
使用命令、UI或者基于CPU使用情况自动快速扩容和缩容应用程序实例,保证应用业务高峰并发时的高可用性;业务低峰时回收资源,以最小成本运行服务。
Kubernetes采用滚动更新策略更新应用,一次更新一个Pod,而不是同时删除所有Pod,如果更新过程中出现问题,将回滚更改,确保升级不会影响业务。
Kubernetes为多个容器提供一个统一访问入口(内部IP地址和一个DNS名称),并且负载均衡关联所有容器,使得用户无需考虑容器IP问题
管理机密数据和应用程序配置,而不需要把敏感数据暴露在镜像里,提高敏感数据安全性。并可以将一些常用的配置存储在Kubernetes中,方便应用程序使用。
挂载外部存储系统,无论是来自本地存储,公有云(如AWS),还是网络存储(如NFS、GlusterFS、Ceph)都作为集群资源的一部分使用,极大提高存储使用灵活性
提供一次性任务,定时任务;满足批量数据处理和分析的场景
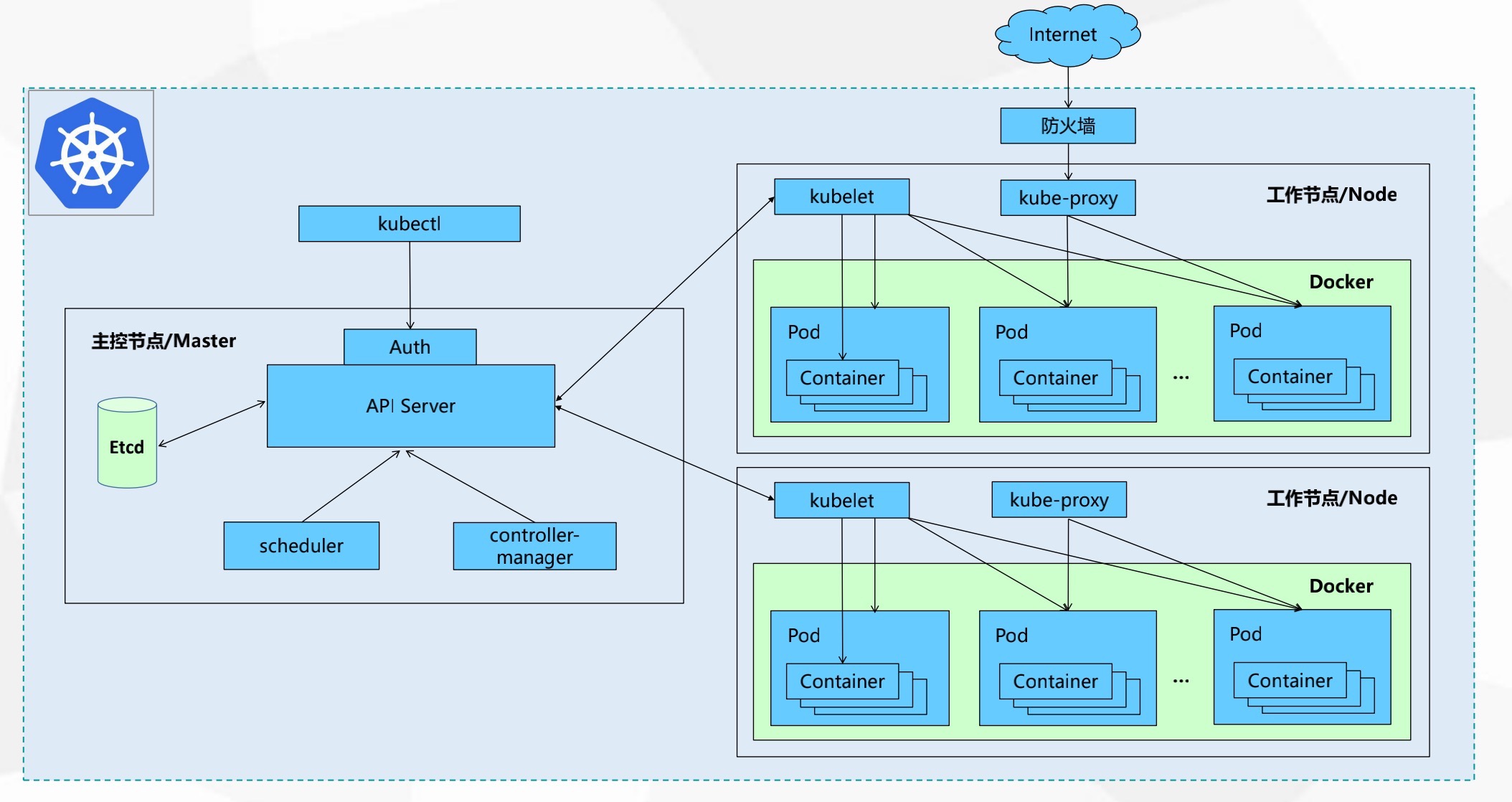
Kubernetes集群架构与组件
Master组件
Kubernetes API,集群的统一入口,各组件协调者,以RESTful API提供接口服务,所有对象资源的增删查改和监听操作都交给APIServer处理后再提交给etcd存储。
处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。
根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点,也可以部署在不同的节点上。
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息。
Node组件
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作
容器运行时
Kubernetes核心概念 Pod
最小部署单元
一组容器的集合
一个Pod中的容器共享网络命名空间
Pod是短暂的,不是持久存在的
Controllers
ReplicaSet:确保预期的Pod副本数量
Deployment:无状态应用部署
StatefulSet:有状态应用部署
DaemonSet:确保所有Node运行同一个Pod
Job:一次性任务
CronJob:定时任务
Service
Label 标签,附加到某个资源上,用于关联对象、查询和筛选
Namespace 命名空间,将对象逻辑上分离
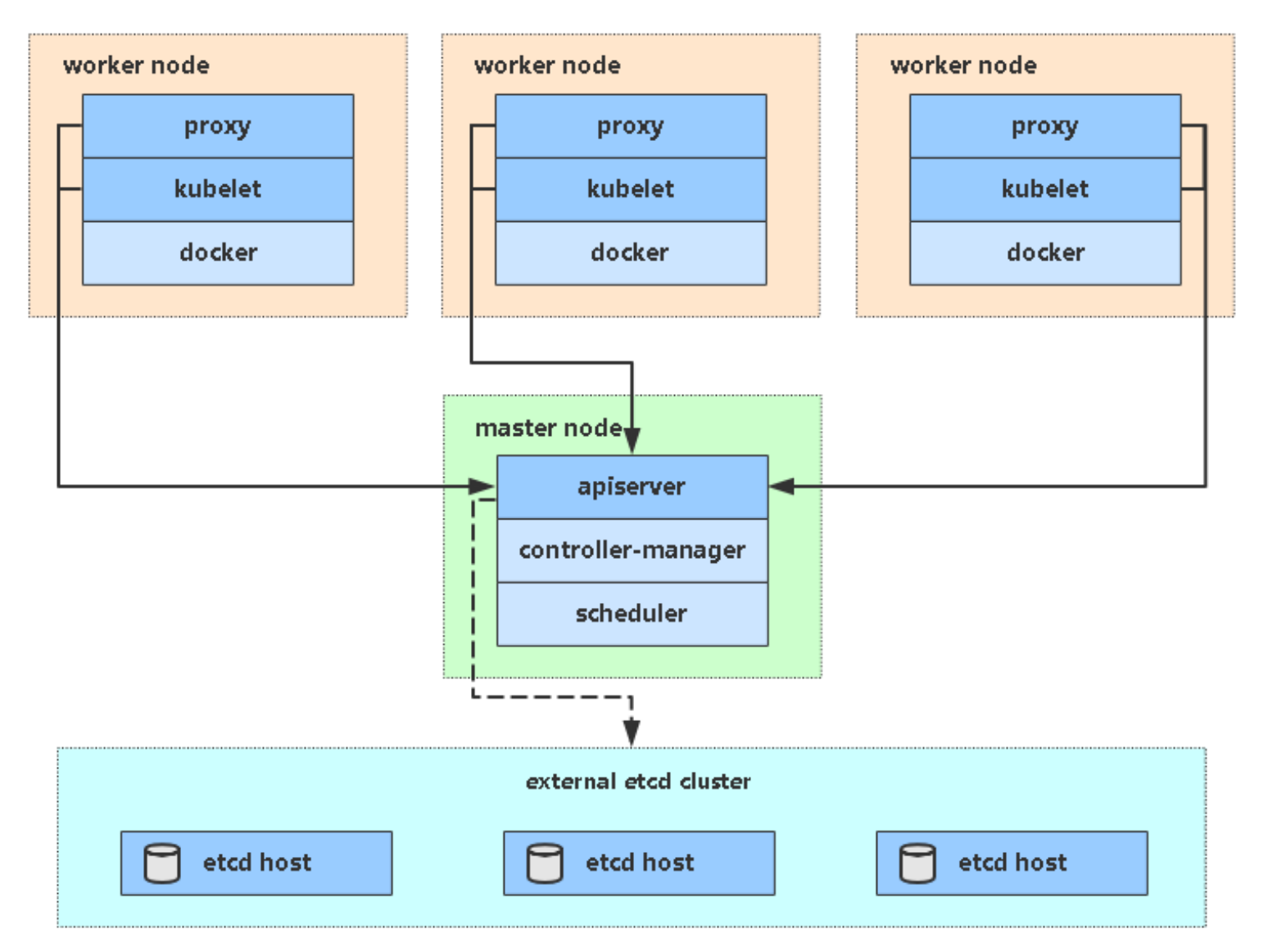
生产环境Kubernetes平台规划 单Master集群
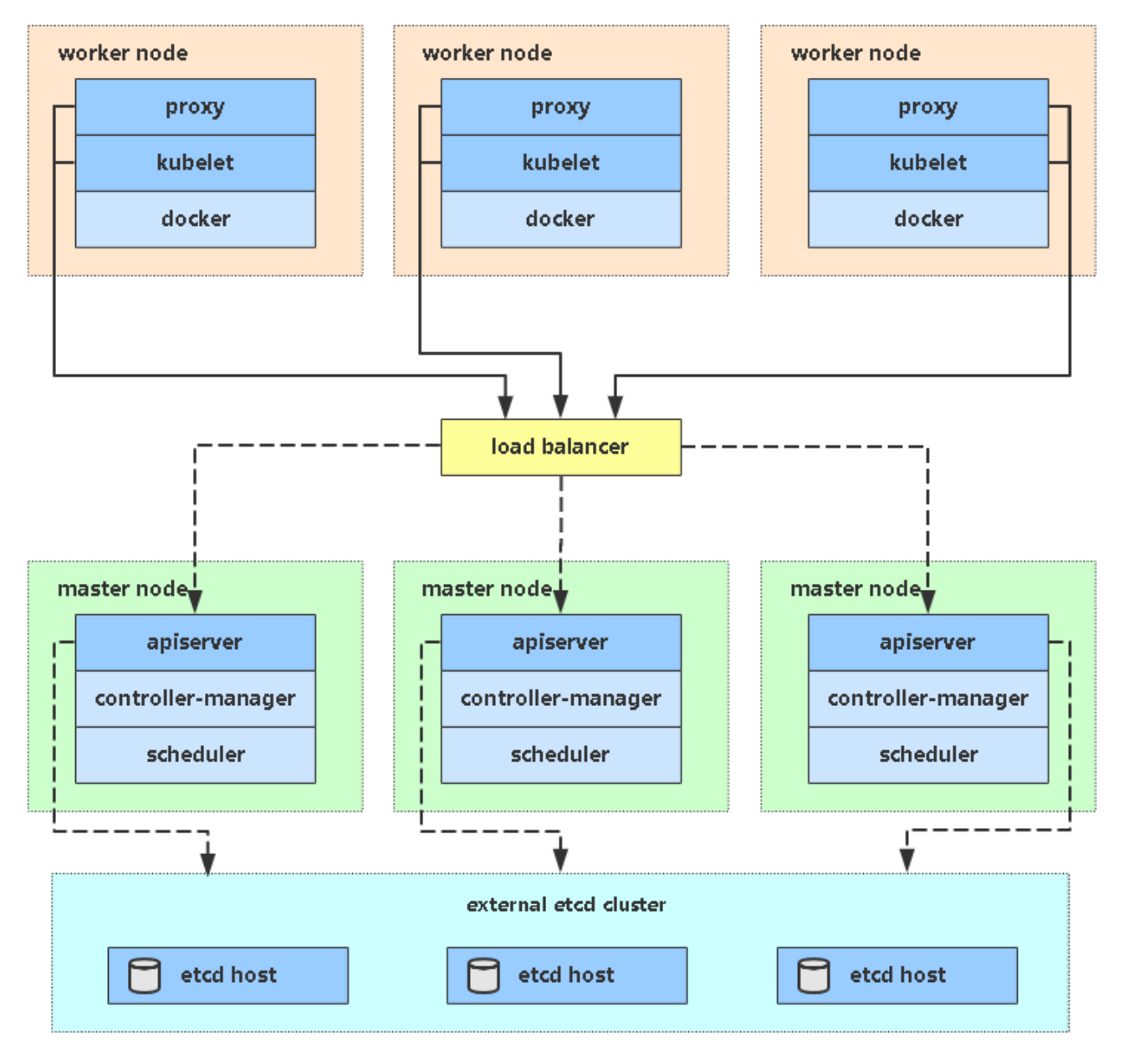
多Master集群(HA)
服务器硬件配置推荐 Mater节点
物理机虚拟机均可,至少1台,高可用集群至少2台(etcd集群必须奇数台)
推荐配置:实验环境2核2G、测试环境2核4G、生产环境8核16G
关闭所有swap分区或不划分swap分区
Node节点
物理机虚拟机均可,大于等于1台
推荐配置:实验环境2核2G、测试环境4核8G、生产环境16核64G
关闭所有swap分区或不划分swap分区
实验环境信息
主机名
配置
操作系统
IP地址
角色
组件
k8s-master1
2核2G
CentOS7.5
10.211.55.4
Master
kube-apiserver
k8s-master2
2核2G
CentOS7.5
10.211.55.7
Master
kube-apiserver
k8s-node1
2核2G
CentOS7.5
10.211.55.5
Node
kubelet
k8s-node2
2核2G
CentOS7.5
10.211.55.6
Node
kubelet
VIP:10.211.55.10
系统初始化 关闭防火墙 1 2 systemctl stop firewalld systemctl disable firewalld
关闭selinux 1 2 setenforce 0 sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
关闭swap 1 2 swapoff -a echo 'swapoff -a ' >> /etc/rc.d/rc.local
配置主机名 1 hostnamectl set-hostname ${HOSTNAME}
添加所有节点的本地host解析 1 2 3 4 5 6 cat >> /etc/hosts << EOF 10.211.55.4 k8s-master1 10.211.55.7 k8s-master2 10.211.55.5 k8s-node1 10.211.55.6 k8s-node2 EOF
安装基础软件包 1 yum install vim net-tools lrzsz unzip dos2unix telnet sysstat iotop pciutils lsof tcpdump psmisc bc wget socat -y
内核开启网络支持 1 2 3 4 5 6 7 8 9 10 11 cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 net.ipv4.ip_nonlocal_bind = 1 net.ipv4.neigh.default.gc_thresh1 = 80000 net.ipv4.neigh.default.gc_thresh2 = 90000 net.ipv4.neigh.default.gc_thresh3 = 100000 EOF modprobe br_netfilter sysctl --system
配置master1到所有节点(包括自身)的ssh免密登录 在master1上执行以下命令生成密钥文件(一路直接回车即可)
然后把公钥拷贝到所有节点(包括自身)
1 2 3 4 ssh-copy-id -i ~/.ssh/id_rsa.pub k8s-master1 ssh-copy-id -i ~/.ssh/id_rsa.pub k8s-master2 ssh-copy-id -i ~/.ssh/id_rsa.pub k8s-node1 ssh-copy-id -i ~/.ssh/id_rsa.pub k8s-node2
在master1上通过ssh命令验证到所有节点(包括自身)均可免密登录
1 2 3 4 ssh k8s-master1 ssh k8s-master2 ssh k8s-node1 ssh k8s-node2
节点之间时间同步 Server端
说明 ntp.aliyun.com)同步即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 timedatectl set-timezone Asia/Shanghai yum install chrony ntpdate -y cp -a /etc/chrony.conf /etc/chrony.conf.bakcat > /etc/chrony.conf << EOF stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 allow 10.211.55.0/24 # 设置为实际环境客户端所属IP网段 smoothtime 400 0.01 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 local stratum 8 manual keyfile /etc/chrony.keys #initstepslew 10 client1 client3 client6 noclientlog logchange 0.5 logdir /var/log/chrony EOF systemctl restart chronyd.service systemctl enable chronyd.service systemctl status chronyd.service
Client端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 timedatectl set-timezone Asia/Shanghai yum install chrony ntpdate -y cp -a /etc/chrony.conf /etc/chrony.conf.baksed -i "s%^server%#server%g" /etc/chrony.conf echo "server 10.211.55.4 iburst" >> /etc/chrony.conf ntpdate 10.211.55.4 systemctl restart chronyd.service systemctl enable chronyd.service systemctl status chronyd.service chronyc sources chronyc tracking
安装CFSSL工具 CFSSL是CloudFlare开源的一款PKI/TLS工具。 CFSSL包含一个命令行工具和一个用于签名,验证并且捆绑TLS证书的HTTP API服务。使用Go语言编写
在其中一台节点(建议用master1)上执行以下命令直接进行安装
1 2 3 4 5 curl -s -L -o /usr/local/bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 curl -s -L -o /usr/local/bin/cfssljson https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 curl -s -L -o /usr/local/bin/cfssl-certinfo https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 chmod +x /usr/local/bin/cfssl*cfssl version
说明 cfssl_linux-amd64、cfssljson_linux-amd64、cfssl-certinfo_linux-amd64并上传到其中一台节点的/root目录下(建议用master1),并执行以下命令安装cfssl
1 2 3 4 5 mv /root/cfssl_linux-amd64 /usr/local/bin/cfsslmv /root/cfssljson_linux-amd64 /usr/local/bin/cfssljsonmv /root/cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfochmod +x /usr/local/bin/cfssl*cfssl version
部署etcd数据库集群 etcd是基于Raft的分布式key-value存储系统,由CoreOS开发,常用于服务发现、共享配置以及并发控制(如leader选举、分布式锁等)。Kubernetes使用 etcd存储所有运行数据。
使用cfssl为etcd生成自签证书 在安装了cfssl工具的节点上执行以下命令为etcd创建对应的ca机构并生成自签证书
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 mkdir /root/etcd-cert && cd /root/etcd-certcat > ca-csr.json << EOF { "CN": "etcd CA", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "ShenZhen", "ST": "ShenZhen" } ] } EOF cat > ca-config.json << EOF { "signing": { "default": { "expiry": "876000h" }, "profiles": { "etcd": { "expiry": "876000h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF cat > etcd-csr.json << EOF { "CN": "etcd", "hosts": [ "10.211.55.4", "10.211.55.5", "10.211.55.6" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "ShenZhen", "ST": "ShenZhen" } ] } EOF cfssl gencert -initca ca-csr.json | cfssljson -bare ca - cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=etcd etcd-csr.json | cfssljson -bare etcd
部署etcd3.3版本 访问https://github.com/etcd-io/etcd/releases 下载etcd3.3版本的二进制包(本文以3.3.18为例),并上传到其中一台etcd节点的/root目录下,然后执行以下命令解压并创建etcd相关目录和配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 cd /root/tar zxf etcd-v3.3.18-linux-amd64.tar.gz -C /opt/ mv /opt/etcd-v3.3.18-linux-amd64/ /opt/etcdmkdir /opt/etcd/binmkdir /opt/etcd/cfgmkdir /opt/etcd/sslcp -a /opt/etcd/etcd* /opt/etcd/bin/cp -a /root/etcd-cert/{ca,etcd,etcd-key}.pem /opt/etcd/ssl/cat > /opt/etcd/cfg/etcd.conf << EOF #[Member] # 自定义此etcd节点的名称,集群内唯一 ETCD_NAME="etcd-1" # 定义etcd数据存放目录 ETCD_DATA_DIR="/var/lib/etcd/default.etcd" # 定义本机和成员之间通信的地址 ETCD_LISTEN_PEER_URLS="https://10.211.55.4:2380" # 定义etcd对外提供服务的地址 ETCD_LISTEN_CLIENT_URLS="https://10.211.55.4:2379" #[Clustering] # 定义该节点成员对等URL地址,且会通告集群的其余成员节点 ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.211.55.4:2380" # 此成员的客户端URL列表,用于通告群集的其余部分 ETCD_ADVERTISE_CLIENT_URLS="https://10.211.55.4:2379" # 集群中所有节点的信息 ETCD_INITIAL_CLUSTER="etcd-1=https://10.211.55.4:2380,etcd-2=https://10.211.55.5:2380,etcd-3=https://10.211.55.6:2380" # 创建集群的token,这个值每个集群保持唯一 ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" # 设置new为初始静态或DNS引导期间出现的所有成员。如果将此选项设置为existing,则etcd将尝试加入现有群集 ETCD_INITIAL_CLUSTER_STATE="new" EOF vim /usr/lib/systemd/system/etcd.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=/opt/etcd/cfg/etcd.conf ExecStart=/opt/etcd/bin/etcd \ --name=${ETCD_NAME} \ --data-dir=${ETCD_DATA_DIR} \ --listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \ --listen-client-urls=${ETCD_LISTEN_CLIENT_URLS} ,http://127.0.0.1:2379 \ --advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \ --initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \ --initial-cluster=${ETCD_INITIAL_CLUSTER} \ --initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \ --initial-cluster-state=new \ --cert-file=/opt/etcd/ssl/etcd.pem \ --key-file=/opt/etcd/ssl/etcd-key.pem \ --peer-cert-file=/opt/etcd/ssl/etcd.pem \ --peer-key-file=/opt/etcd/ssl/etcd-key.pem \ --trusted-ca-file=/opt/etcd/ssl/ca.pem \ --peer-trusted-ca-file=/opt/etcd/ssl/ca.pem Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target
将etcd目录和Service文件拷贝到其余etcd集群节点上,并修改etcd配置文件中的ETCD_NAME、ETCD_LISTEN_PEER_URLS、ETCD_LISTEN_CLIENT_URLS、ETCD_INITIAL_ADVERTISE_PEER_URLS和ETCD_ADVERTISE_CLIENT_URLS参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 scp -r /opt/etcd/ k8s-node1:/opt/ scp -r /usr/lib/systemd/system/etcd.service k8s-node1:/usr/lib/systemd/system/ vim /opt/etcd/cfg/etcd.conf ETCD_NAME="etcd-2" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://10.211.55.5:2380" ETCD_LISTEN_CLIENT_URLS="https://10.211.55.5:2379" ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.211.55.5:2380" ETCD_ADVERTISE_CLIENT_URLS="https://10.211.55.5:2379" ETCD_INITIAL_CLUSTER="etcd-1=https://10.211.55.4:2380,etcd-2=https://10.211.55.5:2380,etcd-3=https://10.211.55.6:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new"
在所有etcd集群节点上启动etcd并设置开机自启
1 2 3 4 5 6 systemctl daemon-reload systemctl enable etcd systemctl start etcd systemctl status etcd
在任意etcd节点上执行以下命令查看集群状态,如果所有节点均处于healthy状态则表示etcd集群部署成功
1 /opt/etcd/bin/etcdctl --ca-file=/opt/etcd/ssl/ca.pem --cert-file=/opt/etcd/ssl/etcd.pem --key-file=/opt/etcd/ssl/etcd-key.pem --endpoints="https://10.211.55.4:2379,https://10.211.55.5:2379,https://10.211.55.6:2379" cluster-health
部署etcd3.4版本 访问https://github.com/etcd-io/etcd/releases 下载etcd3.4版本的二进制包(本文以3.4.3为例),并上传到其中一台etcd节点的/root目录下,然后执行以下命令解压并创建etcd相关目录和配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 cd /root/tar zxf etcd-v3.4.3-linux-amd64.tar.gz -C /opt/ mv /opt/etcd-v3.4.3-linux-amd64/ /opt/etcdmkdir /opt/etcd/binmkdir /opt/etcd/cfgmkdir /opt/etcd/sslcp -a /opt/etcd/etcd* /opt/etcd/bin/cp -a /root/etcd-cert/{ca,etcd,etcd-key}.pem /opt/etcd/ssl/cat > /opt/etcd/cfg/etcd.conf << EOF #[Member] # 自定义此etcd节点的名称,集群内唯一 ETCD_NAME="etcd-1" # 定义etcd数据存放目录 ETCD_DATA_DIR="/var/lib/etcd/default.etcd" # 定义本机和成员之间通信的地址 ETCD_LISTEN_PEER_URLS="https://10.211.55.4:2380" # 定义etcd对外提供服务的地址 ETCD_LISTEN_CLIENT_URLS="https://10.211.55.4:2379,http://127.0.0.1:2379" #[Clustering] # 定义该节点成员对等URL地址,且会通告集群的其余成员节点 ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.211.55.4:2380" # 此成员的客户端URL列表,用于通告群集的其余部分 ETCD_ADVERTISE_CLIENT_URLS="https://10.211.55.4:2379" # 集群中所有节点的信息 ETCD_INITIAL_CLUSTER="etcd-1=https://10.211.55.4:2380,etcd-2=https://10.211.55.5:2380,etcd-3=https://10.211.55.6:2380" # 创建集群的token,这个值每个集群保持唯一 ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" # 设置new为初始静态或DNS引导期间出现的所有成员。如果将此选项设置为existing,则etcd将尝试加入现有群集 ETCD_INITIAL_CLUSTER_STATE="new" # flannel操作etcd使用的是v2的API,而kubernetes操作etcd使用的v3的API,在ETCD3.4版本中默认关闭v2版本,所以为了兼容flannel,要设置开启v2的API ETCD_ENABLE_V2="true" EOF vim /usr/lib/systemd/system/etcd.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=/opt/etcd/cfg/etcd.conf ExecStart=/opt/etcd/bin/etcd \ --cert-file=/opt/etcd/ssl/etcd.pem \ --key-file=/opt/etcd/ssl/etcd-key.pem \ --peer-cert-file=/opt/etcd/ssl/etcd.pem \ --peer-key-file=/opt/etcd/ssl/etcd-key.pem \ --trusted-ca-file=/opt/etcd/ssl/ca.pem \ --peer-trusted-ca-file=/opt/etcd/ssl/ca.pem Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target
将etcd目录和Service文件拷贝到其余etcd集群节点上,并修改etcd配置文件中的ETCD_NAME、ETCD_LISTEN_PEER_URLS、ETCD_LISTEN_CLIENT_URLS、ETCD_INITIAL_ADVERTISE_PEER_URLS和ETCD_ADVERTISE_CLIENT_URLS参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 scp -r /opt/etcd/ k8s-node1:/opt/ scp -r /usr/lib/systemd/system/etcd.service k8s-node1:/usr/lib/systemd/system/ vim /opt/etcd/cfg/etcd.conf ETCD_NAME="etcd-2" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://10.211.55.5:2380" ETCD_LISTEN_CLIENT_URLS="https://10.211.55.5:2379,http://127.0.0.1:2379" ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.211.55.5:2380" ETCD_ADVERTISE_CLIENT_URLS="https://10.211.55.5:2379" ETCD_INITIAL_CLUSTER="etcd-1=https://10.211.55.4:2380,etcd-2=https://10.211.55.5:2380,etcd-3=https://10.211.55.6:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" ETCD_ENABLE_V2="true" EOF
在所有etcd集群节点上设置etcd开机自启并启动etcd
说明
1 2 3 systemctl daemon-reload systemctl enable etcd systemctl start etcd
在任意etcd节点上执行以下命令查看集群状态,如果所有节点均处于healthy状态则表示etcd集群部署成功
1 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/etcd.pem --key=/opt/etcd/ssl/etcd-key.pem --endpoints="https://10.211.55.4:2379,https://10.211.55.5:2379,https://10.211.55.6:2379" endpoint health
卸载etcd 如果安装失败需要卸载重新安装,在所有etcd节点上执行以下命令即可
1 2 3 4 5 systemctl stop etcd systemctl disable etcd rm -rf /opt/etcd/rm -rf /usr/lib/systemd/system/etcd.servicerm -rf /var/lib/etcd/
部署Master组件 使用cfssl为apiserver和kube-proxy生成自签证书 在安装了cfssl工具的节点上执行以下命令为apiserver和kube-proxy创建对应的ca机构并生成自签证书
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 mkdir /root/k8s-cert && cd /root/k8s-certcat > ca-csr.json << EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "ShenZhen", "ST": "ShenZhen", "O": "k8s", "OU": "System" } ] } EOF cat > ca-config.json << EOF { "signing": { "default": { "expiry": "876000h" }, "profiles": { "kubernetes": { "expiry": "876000h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF cat > apiserver-csr.json << EOF { "CN": "kubernetes", "hosts": [ "10.0.0.1", "127.0.0.1", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local", "10.211.55.4", "10.211.55.5", "10.211.55.6", "10.211.55.7", "10.211.55.10" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "ShenZhen", "ST": "ShenZhen", "O": "k8s", "OU": "System" } ] } EOF cat > kube-proxy-csr.json << EOF { "CN": "system:kube-proxy", "hosts": [""], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "ShenZhen", "ST": "ShenZhen", "O": "k8s", "OU": "System" } ] } EOF cfssl gencert -initca ca-csr.json | cfssljson -bare ca - cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes apiserver-csr.json | cfssljson -bare apiserver cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
部署apiserver、controller-manager和scheduler 二进制包下载地址:https://github.com/kubernetes/kubernetes/releases
在每个release版本的CHANGELOG中有每个版本的二进制包下载列表,下载对应平台下的Server Binaries(包含master/node组件),上传到其中一台Master节点的/root目录下(本文以1.16.4为例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 mkdir /opt/kubernetesmkdir /opt/kubernetes/binmkdir /opt/kubernetes/cfgmkdir /opt/kubernetes/sslmkdir /opt/kubernetes/logscd /root/tar zxf kubernetes-server-linux-amd64.tar.gz cp -a /root/kubernetes/server/bin/kube-apiserver /opt/kubernetes/bin/cp -a /root/kubernetes/server/bin/kube-controller-manager /opt/kubernetes/bin/cp -a /root/kubernetes/server/bin/kube-scheduler /opt/kubernetes/bin/cp -a /root/kubernetes/server/bin/kubectl /usr/local/bin/cp -a /root/k8s-cert/{ca,ca-key,apiserver,apiserver-key}.pem /opt/kubernetes/ssl/cat > /opt/kubernetes/cfg/kube-apiserver.conf << EOF KUBE_APISERVER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --etcd-servers=https://10.211.55.4:2379,https://10.211.55.5:2379,https://10.211.55.6:2379 \\ --bind-address=10.211.55.4 \\ --secure-port=6443 \\ --advertise-address=10.211.55.4 \\ --allow-privileged=true \\ --service-cluster-ip-range=10.0.0.0/24 \\ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\ --authorization-mode=RBAC,Node \\ --enable-bootstrap-token-auth=true \\ --token-auth-file=/opt/kubernetes/cfg/token.csv \\ --service-node-port-range=30000-32767 \\ --kubelet-client-certificate=/opt/kubernetes/ssl/apiserver.pem \\ --kubelet-client-key=/opt/kubernetes/ssl/apiserver-key.pem \\ --tls-cert-file=/opt/kubernetes/ssl/apiserver.pem \\ --tls-private-key-file=/opt/kubernetes/ssl/apiserver-key.pem \\ --client-ca-file=/opt/kubernetes/ssl/ca.pem \\ --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\ --etcd-cafile=/opt/etcd/ssl/ca.pem \\ --etcd-certfile=/opt/etcd/ssl/etcd.pem \\ --etcd-keyfile=/opt/etcd/ssl/etcd-key.pem \\ --audit-log-maxage=30 \\ --audit-log-maxbackup=3 \\ --audit-log-maxsize=100 \\ --audit-log-path=/opt/kubernetes/logs/k8s-audit.log \\ --default-not-ready-toleration-seconds=20 \\ --default-unreachable-toleration-seconds=20" EOF
参数
说明
--logtostderr日志是否输出到标准错误输出
--v=2日志级别0-8,数字越大,日志越详细
--log-dir设置日志存放目录
--etcd-servers指定etcd服务的URL
--bind-addressapiserver监听地址
--secure-portapiserver监听端口,默认为6443
--advertise-address通告地址,让其他节点通过此IP来连接apiserver
--allow-privileged开启容器的privileged权限
--service-cluster-ip-rangeKubernetes集群中Service的虚拟IP地址范围,以CIDR格式表示,例如169.169.0.0/16,该IP范围不能与部署机器的IP地址有重合
--enable-admission-pluginsKubernetes集群的准入控制设置,各控制模块以插件的形式依次生效。
--authorization-mode授权模式
--enable-bootstrap-token-auth启用bootstrap token认证
--service-node-port-rangeKubernetes集群中Service可使用的端口号范围,默认值为30000~32767
--kubelet-client-certificate、--kubelet-client-key连接kubelet使用的证书和私钥
--tls-cert-file、--tls-private-key-file、--client-ca-file、--service-account-key-fileapiserver启用https所用的证书和私钥
--etcd-cafile、--etcd-certfile、--etcd-keyfile连接etcd所使用的证书
--audit-log-maxage、--audit-log-maxbackup、--audit-log-maxsize、--audit-log-path日志轮转、日志路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 cat > /opt/kubernetes/cfg/kube-controller-manager.conf << EOF KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --leader-elect=true \\ --master=127.0.0.1:8080 \\ --address=127.0.0.1 \\ --allocate-node-cidrs=true \\ --cluster-cidr=10.244.0.0/16 \\ --service-cluster-ip-range=10.0.0.0/24 \\ --cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\ --cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\ --root-ca-file=/opt/kubernetes/ssl/ca.pem \\ --service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\ --experimental-cluster-signing-duration=876000h0m0s \\ --node-monitor-grace-period=20s \\ --node-monitor-period=2s \\ --node-startup-grace-period=20s \\ --pod-eviction-timeout=20s \\ --node-eviction-rate=1" EOF
参数
说明
--leader-elect启用自动选举
--master连接apiserver的IP,127.0.0.1:8080是apiserver默认监听的,用于让其他组件通过此地址连接
--address配置controller-manager监听地址,不需要对外
--allocate-node-cidrs允许安装CNI插件,自动分配IP
--cluster-cidr集群pod的IP段,要与与CNI插件的IP段一致
--service-cluster-ip-rangeService Cluster IP段,与kube-apiserver.conf中的--service-cluster-ip-range参数配置保持一致
--cluster-signing-cert-file、--cluster-signing-key-file用于集群签名的ca证书和私钥
--root-ca-file、--service-account-private-key-file签署service account的证书和私钥
--experimental-cluster-signing-duration签发证书的有效期
1 2 3 4 5 6 7 8 9 cat > /opt/kubernetes/cfg/kube-scheduler.conf << EOF KUBE_SCHEDULER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --leader-elect=true \\ --master=127.0.0.1:8080 \\ --address=127.0.0.1" EOF
参数
说明
--leader-elect启用自动选举
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 cat > /usr/lib/systemd/system/kube-apiserver.service << EOF [Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=/opt/kubernetes/cfg/kube-apiserver.conf ExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=/opt/kubernetes/cfg/kube-controller-manager.conf ExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF cat > /usr/lib/systemd/system/kube-scheduler.service << EOF [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler.conf ExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF
随机生成一个32位字符串,用以创建token.csv文件
1 2 3 token=`head -c 16 /dev/urandom | od -An -t x | tr -d ' ' ` echo "$token ,kubelet-bootstrap,10001,'system:node-bootstrapper'" > /opt/kubernetes/cfg/token.csv
说明 bootstrap.kubeconfig配置文件里的token一致
设置api-server、controller-manager、scheduler开机自启并启动
1 2 3 4 5 6 7 8 9 10 systemctl daemon-reload systemctl enable kube-apiserver systemctl enable kube-controller-manager systemctl enable kube-scheduler systemctl start kube-apiserver systemctl start kube-controller-manager systemctl start kube-scheduler systemctl status kube-apiserver systemctl status kube-controller-manager systemctl status kube-scheduler
在其中一台master上执行以下命令为kubectl TLS Bootstrapping授权
1 kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
此时你可以通过执行kubectl get cs获取Kubernetes的各服务端组件状态看是否Healthy,但是如果你安装的是1.16版本,你会发现你的输出内容有一些变化,类似如下:
1 2 3 4 5 6 7 NAME AGE controller-manager <unknown> scheduler <unknown> etcd-0 <unknown> etcd-2 <unknown> etcd-1 <unknown>
起初以为集群部署有问题,但是通过kubectl get cs -o yaml发现status、message等信息都有,只是没有打印出来。所以在网上搜索相关文章,最后在这里 找到了原因,原来这是1.16的bug!!!坐等官方修复吧,当然针对此问题,大佬也给出了临时解决方法,参考下方:
1 kubectl get cs -o=go-template='{{printf "|NAME|STATUS|MESSAGE|\n"}}{{range .items}}{{$name := .metadata.name}}{{range .conditions}}{{printf "|%s|%s|%s|\n" $name .status .message}}{{end}}{{end}}'
部署Node组件 安装Docker 二进制包下载地址:https://download.docker.com/linux/static/stable/
到对应平台的目录下载所需版本的Docker二进制包,并上传到所有Node节点的/root目录下(本文以x86平台下的18.09.9为例),然后依次在所有Node节点上执行以下命令安装Docker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 cd /root/tar zxf docker-18.09.9.tgz chmod 755 docker/*cp -a docker/* /usr/bin/cat > /usr/lib/systemd/system/docker.service << EOF [Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service containerd.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP \$MAINPID TimeoutSec=0 RestartSec=2 Restart=always StartLimitBurst=3 StartLimitInterval=60s LimitNOFILE=1048576 LimitNPROC=1048576 LimitCORE=infinity TasksMax=infinity Delegate=yes KillMode=process [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl start docker systemctl enable docker systemctl status docker
部署kubelet和kube-proxy 二进制包下载地址:https://github.com/kubernetes/kubernetes/releases
在每个release版本的CHANGELOG中有每个版本的二进制包下载列表,下载对应平台下的Server Binaries(包含master/node组件),上传到所有Node节点的/root目录下(本文以1.16.4为例),然后依次在所有Node节点上执行以下操作安装kubelet和kube-proxy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 mkdir -p /opt/kubernetesmkdir -p /opt/kubernetes/binmkdir -p /opt/kubernetes/cfgmkdir -p /opt/kubernetes/sslmkdir -p /opt/kubernetes/logscd /root/tar zxf kubernetes-server-linux-amd64.tar.gz cp -a /root/kubernetes/server/bin/kubelet /opt/kubernetes/bin/cp -a /root/kubernetes/server/bin/kube-proxy /opt/kubernetes/bin/cat > /opt/kubernetes/cfg/kubelet.conf << EOF KUBELET_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --hostname-override=k8s-node1 \\ --network-plugin=cni \\ --kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\ --bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\ --config=/opt/kubernetes/cfg/kubelet-config.yml \\ --cert-dir=/opt/kubernetes/ssl" EOF cat > /opt/kubernetes/cfg/bootstrap.kubeconfig << EOF apiVersion: v1 clusters: - cluster: certificate-authority: /opt/kubernetes/ssl/ca.pem server: https://10.211.55.4:6443 name: kubernetes contexts: - context: cluster: kubernetes user: kubelet-bootstrap name: default current-context: default kind: Config preferences: {} users: - name: kubelet-bootstrap user: token: 65cc0bcbe77f4877f288e5604529f384 EOF cat > /opt/kubernetes/cfg/kubelet-config.yml << EOF kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 address: 0.0.0.0 port: 10250 readOnlyPort: 10255 cgroupDriver: cgroupfs clusterDNS: - 10.0.0.2 clusterDomain: cluster.local failSwapOn: false authentication: anonymous: enabled: false webhook: cacheTTL: 2m0s enabled: true x509: clientCAFile: /opt/kubernetes/ssl/ca.pem authorization: mode: Webhook webhook: cacheAuthorizedTTL: 5m0s cacheUnauthorizedTTL: 30s evictionHard: imagefs.available: 15% memory.available: 100Mi nodefs.available: 10% nodefs.inodesFree: 5% maxOpenFiles: 1000000 maxPods: 110 EOF cat > /opt/kubernetes/cfg/kube-proxy.conf << EOF KUBE_PROXY_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --config=/opt/kubernetes/cfg/kube-proxy-config.yml" EOF cat > /opt/kubernetes/cfg/kube-proxy.kubeconfig << EOF apiVersion: v1 clusters: - cluster: certificate-authority: /opt/kubernetes/ssl/ca.pem server: https://10.211.55.4:6443 name: kubernetes contexts: - context: cluster: kubernetes user: kube-proxy name: default current-context: default kind: Config preferences: {} users: - name: kube-proxy user: client-certificate: /opt/kubernetes/ssl/kube-proxy.pem client-key: /opt/kubernetes/ssl/kube-proxy-key.pem EOF cat > /opt/kubernetes/cfg/kube-proxy-config.yml << EOF kind: KubeProxyConfiguration apiVersion: kubeproxy.config.k8s.io/v1alpha1 address: 0.0.0.0 metricsBindAddress: 0.0.0.0:10249 clientConnection: kubeconfig: /opt/kubernetes/cfg/kube-proxy.kubeconfig hostnameOverride: k8s-node1 clusterCIDR: 10.0.0.0/24 mode: ipvs ipvs: scheduler: "rr" iptables: masqueradeAll: true EOF yum install ipvsadm -y cat > /usr/lib/systemd/system/kubelet.service << EOF [Unit] Description=Kubernetes Kubelet After=docker.service Wants=docker.service [Service] EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf ExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF cat > /usr/lib/systemd/system/kube-proxy.service << EOF [Unit] Description=Kubernetes Proxy After=network.target [Service] EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf ExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF
从上面安装了cfssl工具的主机上拷贝ca证书和kube-proxy的自签证书和私钥到所有Node节点的/opt/kubernetes/ssl目录下
1 2 cd /root/k8s-cert/scp -r ca.pem kube-proxy.pem kube-proxy-key.pem k8s-node1:/opt/kubernetes/ssl/
设置kubelet和kube-proxy开机自启并启动
1 2 3 4 5 6 7 systemctl daemon-reload systemctl enable kubelet systemctl enable kube-proxy systemctl start kubelet systemctl start kube-proxy systemctl status kubelet systemctl status kube-proxy
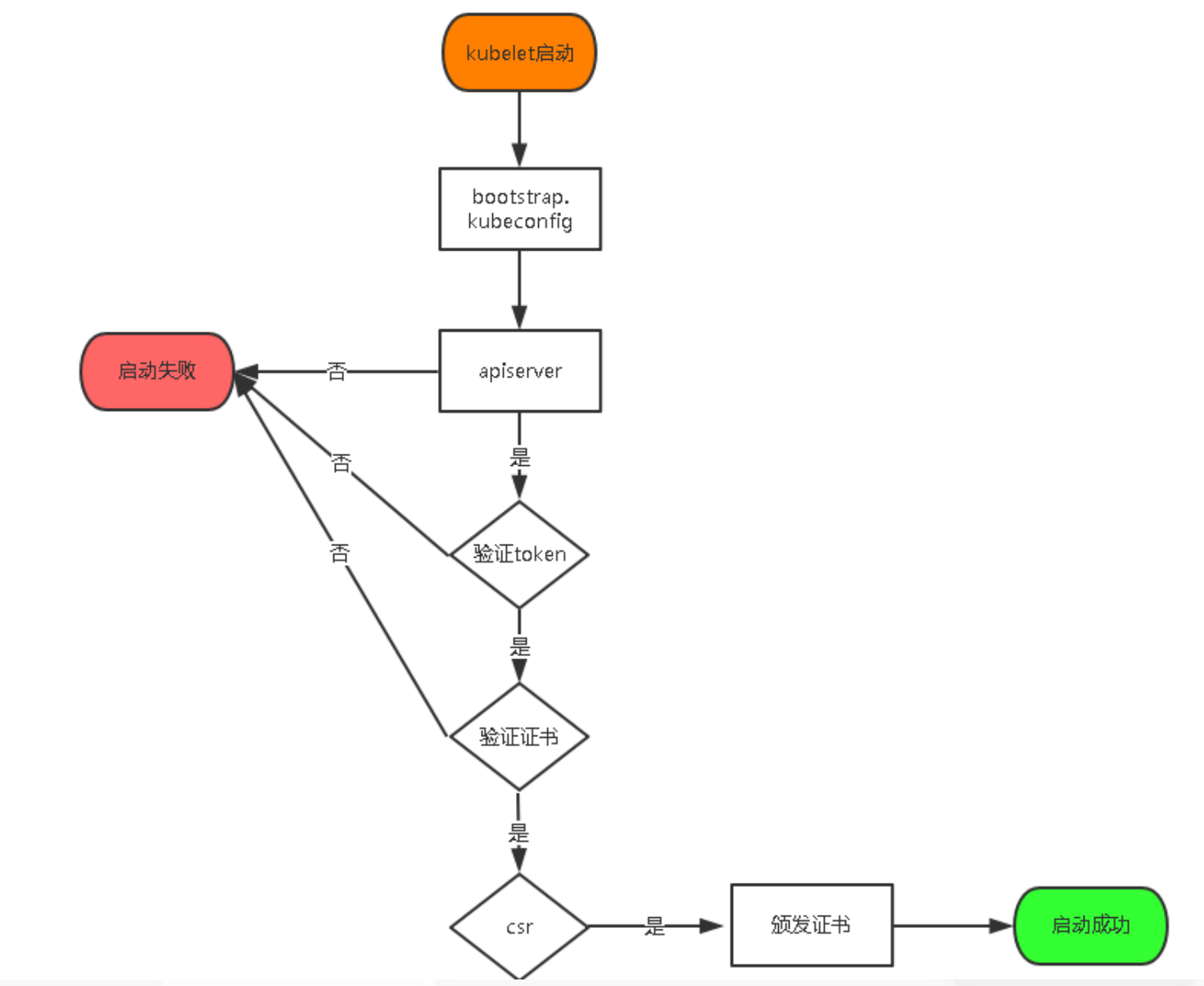
允许给Node颁发证书 当kubelet和kube-proxy成功启动后,此时在任意一台master节点上执行kubectl get csr可以看到有新的节点请求颁发证书(CONDITION字段处于Pending状态),执行以下命令允许给Node颁发证书
1 2 kubectl certificate approve node-csr-vCjAOsDYkXe4Af4gR-NBikSm4yIG00XV5zLjBZgzmQk
授权颁发证书后,在任意一台master节点执行kubectl get node能看到Node节点都还处于NotReady状态,这是因为现在还没安装网络插件
补充知识点 hostname-override配置参数漏修改,导致授权后master无法正常获取到Node节点信息,除了修改kubelet.conf的--hostname-override配置和kube-proxy-config.yml的hostnameOverride配置外,还需要将kubelet.kubeconfig文件(这个文件是master认证后客户端自动生成的)删除,才可重新申请授权,否则报错信息类似如下:
1 kubelet_node_status.go:94] Unable to register node "k8s-node2" with API server: nodes "k8s-node2" is forbidden: node "k8s-node1" is not allowed to modify node "k8s-node2"
2.TLS Bootstrapping 机制流程(Kubelet)
1 2 kubectl drain 10.211.55.6 --delete-local-data kubectl delete node 10.211.55.6
在Node节点操作
1 2 3 4 rm -rf /opt/kubernetes/cfg/kubelet.kubeconfigrm -rf /opt/kubernetes/ssl/kubelet*systemctl restart kubelet systemctl restart kube-proxy
在Master节点重新授权
1 2 kubectl get csr kubectl certificate approve xxxx
部署CNI网络 二进制下载地址:https://github.com/containernetworking/plugins/releases
下载所需平台的最新版本的CNI二进制包并上传到node节点的/root目录下
1 2 3 4 5 6 7 mkdir -p /opt/cni/binmkdir -p /etc/cni/net.dcd /root/tar zxf cni-plugins-linux-amd64-v0.8.3.tgz -C /opt/cni/bin/
确保kubelet启用CNI
1 2 cat /opt/kubernetes/cfg/kubelet.conf |grep network-plugin--network-plugin=cni \
Kubernetes支持多种网络类型,详细可参考以下文档:
本文将介绍Flannel网络的安装方法
在任意一台master节点执行以下命令下载Flannel的资源清单文件
1 2 cd /root/wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
根据实际环境情况修改kube-flannel.yml文件,比如Network、Backend、hostNetwork配置等等,修改完成后进行安装
说明 Network指定的网段要与/opt/kubernetes/cfg/kube-controller-manager.conf中的--cluster-cidr参数指定的网段一致
1 2 cd /root/kubectl apply -f kube-flannel.yml
查看Flannel的pod创建情况,待所有pod都处于Running状态后表示CNI部署完成
1 watch kubectl get pods -n kube-system -o wide
授权apiserver访问kubelet 为提供安全性,kubelet禁止匿名访问,必须授权才可以。一个常见的表现就是无法通过kubectl logs查看pod的日志,错误输出类似如下:
Error from server (Forbidden): Forbidden (user=kubernetes, verb=get, resource=nodes, subresource=proxy) ( pods/log kube-flannel-ds-amd64-cdmcd)
在任意一台master节点上执行以下命令进行授权
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 cat > /root/apiserver-to-kubelet-rbac.yaml << EOF apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:kube-apiserver-to-kubelet rules: - apiGroups: - "" resources: - nodes/proxy - nodes/stats - nodes/log - nodes/spec - nodes/metrics - pods/log verbs: - "*" --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: system:kube-apiserver namespace: "" roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:kube-apiserver-to-kubelet subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: kubernetes EOF kubectl apply -f /root/apiserver-to-kubelet-rbac.yaml
环境测试验证 在任意一个master节点上执行以下命令创建一个nginx pod并暴露端口测试是否可以从外部正常访问
1 2 3 4 5 6 7 8 9 10 kubectl create deployment web --image=nginx kubectl expose deployment web --port=80 --type =NodePort kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE web NodePort 10.0.0.200 <none> 80:30174/TCP 4s
浏览器访问:http://<Node_IP>:30174如果能正常返回nginx欢迎页面,则表示环境一切正常。
说明
1 2 kubectl delete service web kubectl delete deployment web
部署CoreDNS 部署CoreDNS主要是为了给Kubernetes的Service提供DNS解析服务,使得程序可以通过Service的名称进行访问
DNS服务监视Kubernetes API,为每一个Service创建DNS记录用于域名解析。
ClusterIP A记录格式:<service-name>.<namespace-name>.svc.<domain_suffix>,示例:my-svc.my-namespace.svc.cluster.local
使用kubeadm方式部署的Kubernetes会自动安装CoreDNS,二进制部署方式则需要自行安装
从Github地址上下载coredns.yaml.base文件到任意master节点的/root/目录下,并重命名为coredns.yaml,然后参考下方标注修改其中的部分参数
__MACHINE_GENERATED_WARNING__替换为This is a file generated from the base underscore template file: coredns.yaml.base__PILLAR__DNS__DOMAIN__或__DNS__DOMAIN__替换为cluster.local,若要使用非默认域名如koenli.net记得要与node节点上/opt/kubernetes/cfg/kubelet-config.yml文件中的clusterDomain参数保持一致,并要调整api-server证书中的hosts字段值并重新颁发证书__PILLAR__DNS__MEMORY__LIMIT__或__DNS__MEMORY__LIMIT__替换为170Mi,此内存限制的值可根据实际环境资源进行调整__PILLAR__DNS__SERVER__或__DNS__SERVER__替换为10.0.0.2,此IP地址需要与Node节点上/opt/kubernetes/cfg/kubelet-config.yml文件中配置的clusterDNS字段的IP一致
以下为我替换后最终的文件内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 apiVersion: v1 kind: ServiceAccount metadata: name: coredns namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: kubernetes.io/bootstrapping: rbac-defaults addonmanager.kubernetes.io/mode: Reconcile name: system:coredns rules: - apiGroups: - "" resources: - endpoints - services - pods - namespaces verbs: - list - watch - apiGroups: - "" resources: - nodes verbs: - get --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" labels: kubernetes.io/bootstrapping: rbac-defaults addonmanager.kubernetes.io/mode: EnsureExists name: system:coredns roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:coredns subjects: - kind: ServiceAccount name: coredns namespace: kube-system --- apiVersion: v1 kind: ConfigMap metadata: name: coredns namespace: kube-system labels: addonmanager.kubernetes.io/mode: EnsureExists data: Corefile: | .:53 { errors health { lameduck 5s } ready kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 forward . /etc/resolv.conf cache 30 loop reload loadbalance } --- apiVersion: apps/v1 kind: Deployment metadata: name: coredns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "CoreDNS" spec: strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 selector: matchLabels: k8s-app: kube-dns template: metadata: labels: k8s-app: kube-dns annotations: seccomp.security.alpha.kubernetes.io/pod: 'runtime/default' spec: priorityClassName: system-cluster-critical serviceAccountName: coredns tolerations: - key: "CriticalAddonsOnly" operator: "Exists" nodeSelector: beta.kubernetes.io/os: linux containers: - name: coredns image: k8s.gcr.io/coredns:1.6.5 imagePullPolicy: IfNotPresent resources: limits: memory: 170Mi requests: cpu: 100m memory: 70Mi args: [ "-conf" , "/etc/coredns/Corefile" ] volumeMounts: - name: config-volume mountPath: /etc/coredns readOnly: true ports: - containerPort: 53 name: dns protocol: UDP - containerPort: 53 name: dns-tcp protocol: TCP - containerPort: 9153 name: metrics protocol: TCP livenessProbe: httpGet: path: /health port: 8080 scheme: HTTP initialDelaySeconds: 60 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 5 readinessProbe: httpGet: path: /ready port: 8181 scheme: HTTP securityContext: allowPrivilegeEscalation: false capabilities: add: - NET_BIND_SERVICE drop: - all readOnlyRootFilesystem: true dnsPolicy: Default volumes: - name: config-volume configMap: name: coredns items: - key: Corefile path: Corefile --- apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system annotations: prometheus.io/port: "9153" prometheus.io/scrape: "true" labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "CoreDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.0 .0 .2 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP - name: metrics port: 9153 protocol: TCP
执行以下命令进行安装
1 kubectl apply -f /root/coredns.yaml
查看CoreDNS的pod创建情况,待所有Pod均为Running状态后表示部署完成
1 watch kubectl get pod -n kube-system
在任意master节点上执行以下命令创建一个busybox容器,在容器中ping service的名称看是否可以正常解析出IP地址,如果可以则说明DNS服务部署成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 cat > /root/bs.yaml << EOF apiVersion: v1 kind: Pod metadata: name: busybox namespace: default spec: containers: - image: busybox:1.28.4 command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always EOF kubectl apply -f /root/bs.yaml watch kubectl get pods kubectl exec -ti busybox sh / Server: 10.0.0.2 Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local Name: kubernetes Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local / kubectl delete -f /root/bs.yaml
部署Kubernetes Dashboard 在任意一台master节点上下载Kubernetes Dashboard的yaml文件到/root目录下
说明 Github地址 获取对应版本的yaml文件下载地址
1 2 cd /root/wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta6/aio/deploy/recommended.yaml
编辑recommended.yaml文件,找到kubernetes-dashboard这个Service的部分,设置其type为NodePort,nodePort为30001(可自定义)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ... kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard spec: type: NodePort ports: - port: 443 targetPort: 8443 nodePort: 30001 selector: k8s-app: kubernetes-dashboard ...
修改完成后,执行以下命令部署Kubernetes Dashboard
1 kubectl apply -f /root/recommended.yaml
查看Kubernetes Dashboard的pod创建情况,待所有pod都处于Running状态后再继续下面的步骤
1 watch kubectl get pods -n kubernetes-dashboard
创建service account并绑定默认cluster-admin管理员集群角色
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 cat > /root/dashboard-adminuser.yaml << EOF apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard EOF kubectl apply -f /root/dashboard-adminuser.yaml
获取登录token
1 kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}' )
使用上面输出的token登录Kubernetes Dashboard(https://<NODE_IP>:30001)。
说明
说明 secret,并用自签证书创建新的secret(注意修改自签证书的路径是否与实际环境一致)
1 2 kubectl delete secret kubernetes-dashboard-certs -n kubernetes-dashboard kubectl create secret generic kubernetes-dashboard-certs --from-file=/opt/kubernetes/ssl/apiserver-key.pem --from-file=/opt/kubernetes/ssl/apiserver.pem -n kubernetes-dashboard
2.修改/root/recommended.yaml文件,在args下面指定证书文件和Key文件(搜索auto-generate-certificates即可跳转到对应位置)
1 2 3 4 5 args: - --auto-generate-certificates - --tls-key-file=apiserver-key.pem - --tls-cert-file=apiserver.pem
3.重新应用recommended.yaml
1 kubectl apply -f /root/recommended.yaml
4.确认Kubernetes Dashboard的pod都处于Running状态
1 watch kubectl get pods -n kubernetes-dashboard
5.重新访问https://<NODE_IP>:30001
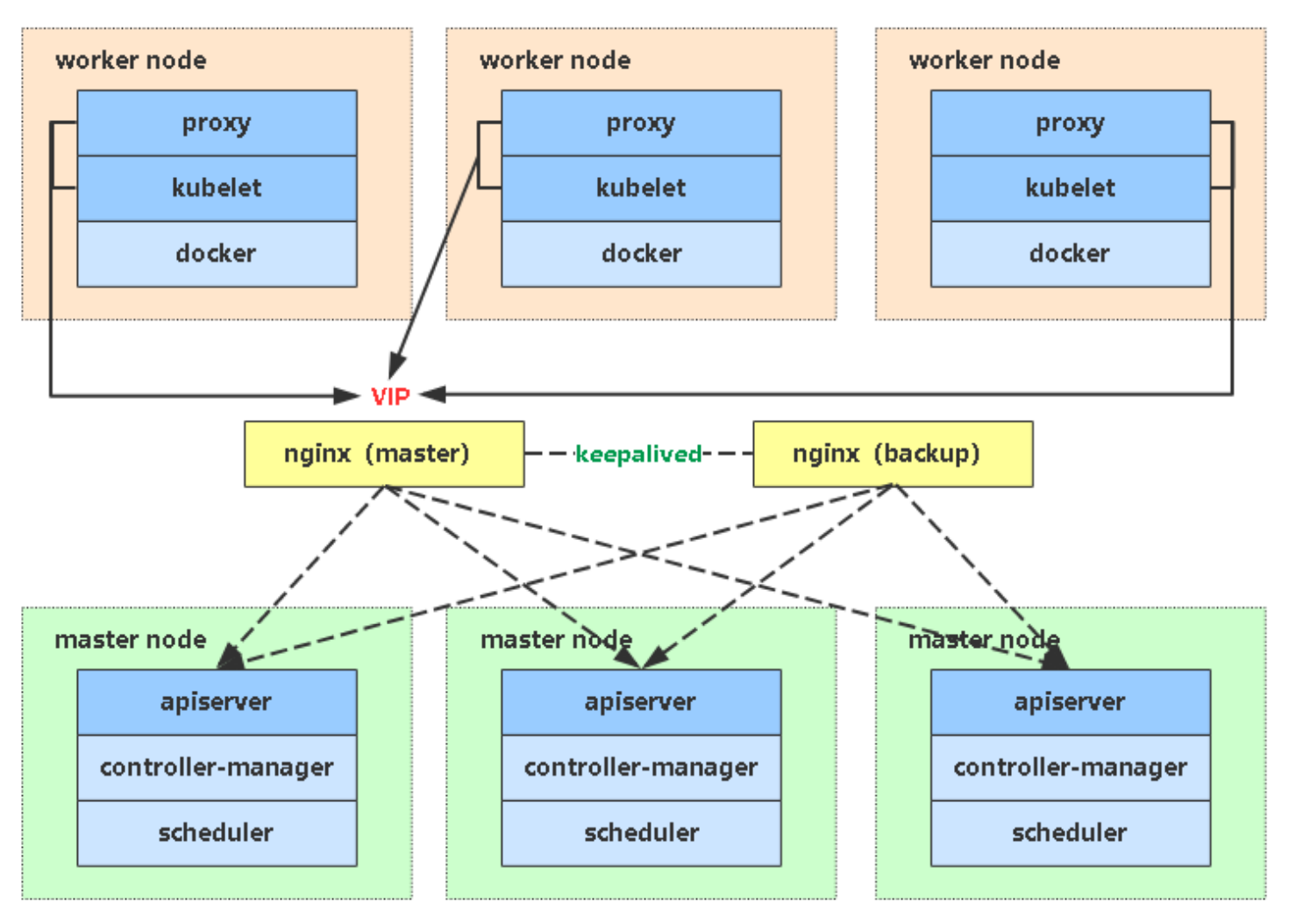
到目前为止一套单Master+2个Node的Kubernetes集群全部搭建完成,但是Master存在单点故障,因此在实际生产环境,我们需要部署多个Master节点,并在Master之前增加一层负载均衡(可通过Nginx、LVS、HAproxy实现),同时为了避免负载均衡存在单点故障,通过Keepalived来实现负载均衡的主备,这样就能保证整个集群不存在单点故障,所有组件均有高可用。
接下来我们将扩容一台Master节点,并通过Nginx和Keepalived实现高可用的负载均衡。
Master高可用 部署Master组件(同Master1一致)
说明
将master1上的kubernetes工作目录、etc工作目录下的ssl目录(证书和私钥文件)、Master组件的Service文件和kubectl二进制文件拷贝到新增Master节点的对应目录下
1 2 3 4 5 6 scp -r /opt/kubernetes/ k8s-master2:/opt/ ssh k8s-master2 rm -rf /opt/kubernetes/logs/* ssh k8s-master2 mkdir /opt/etcd scp -r /opt/etcd/ssl/ k8s-master2:/opt/etcd/ scp -r /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service k8s-master2:/usr/lib/systemd/system/ scp -r /usr/local/bin/kubectl k8s-master2:/usr/local/bin/
修改新Master节点上apiserver配置文件中的--bind-address和--advertise-address参数为本机IP
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 vim /opt/kubernetes/cfg/kube-apiserver.conf KUBE_APISERVER_OPTS="--logtostderr=false \ --v=2 \ --log-dir=/opt/kubernetes/logs \ --etcd-servers=https://10.211.55.4:2379,https://10.211.55.5:2379,https://10.211.55.6:2379 \ --bind-address=10.211.55.7 \ --secure-port=6443 \ --advertise-address=10.211.55.7 \ --allow-privileged=true \ --service-cluster-ip-range=10.0.0.0/24 \ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \ --authorization-mode=RBAC,Node \ --enable-bootstrap-token-auth=true \ --token-auth-file=/opt/kubernetes/cfg/token.csv \ --service-node-port-range=30000-32767 \ --kubelet-client-certificate=/opt/kubernetes/ssl/apiserver.pem \ --kubelet-client-key=/opt/kubernetes/ssl/apiserver-key.pem \ --tls-cert-file=/opt/kubernetes/ssl/apiserver.pem \ --tls-private-key-file=/opt/kubernetes/ssl/apiserver-key.pem \ --client-ca-file=/opt/kubernetes/ssl/ca.pem \ --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \ --etcd-cafile=/opt/etcd/ssl/ca.pem \ --etcd-certfile=/opt/etcd/ssl/etcd.pem \ --etcd-keyfile=/opt/etcd/ssl/etcd-key.pem \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/opt/kubernetes/logs/k8s-audit.log \ --default-not-ready-toleration-seconds=20 \ --default-unreachable-toleration-seconds=20"
设置api-server、controller-manager、scheduler开机自启并启动
1 2 3 4 5 6 7 8 9 10 systemctl daemon-reload systemctl enable kube-apiserver systemctl enable kube-controller-manager systemctl enable kube-scheduler systemctl start kube-apiserver systemctl start kube-controller-manager systemctl start kube-scheduler systemctl status kube-apiserver systemctl status kube-controller-manager systemctl status kube-scheduler
在新Master节点上执行以下命令如果能正常获取到node节点信息说明新Master节点新增成功
部署Nginx负载均衡 Nginx RPM下载地址:http://nginx.org/packages/rhel/7/x86_64/RPMS/
下载Nginx安装包并上传到规划部署Nginx的机器的/root目录下,并进行安装
1 2 cd /root/rpm -ivh nginx-1.16.1-1.el7.ngx.x86_64.rpm
配置Nginx配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 vim /etc/nginx/nginx.conf ...... events { worker_connections 1024; } stream { log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent' ; access_log /var/log/nginx/k8s-access.log main; upstream k8s-apiserver { server 10.211.55.4:6443; server 10.211.55.7:6443; } server { listen 8443; proxy_pass k8s-apiserver; } } http { include /etc/nginx/mime.types; default_type application/octet-stream; ......
设置Nginx开机自启并启动
1 2 3 systemctl enable nginx systemctl start nginx systemctl status nginx
部署Keepalived 主节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 yum install keepalived -y cp -a /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bakcat > /etc/keepalived/keepalived.conf << EOF global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface eth0 # 接口名称 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 100 # 优先级,备服务器设置 90 advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.211.55.10/24 } track_script { check_nginx } } EOF vim /etc/keepalived/check_nginx.sh count=$(ps -ef |grep nginx |egrep -cv "grep|$$" ) if [ "$count " -eq 0 ];then exit 1 else exit 0 fi chmod +x /etc/keepalived/check_nginx.sh
设置Keepalived开机自启并启动
1 2 3 systemctl enable keepalived systemctl start keepalived systemctl status keepalived
备节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 yum install keepalived -y cp -a /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bakcat > /etc/keepalived/keepalived.conf << EOF global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_BACKUP } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state BACKUP interface eth0 # 接口名称 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 90 # 优先级,备服务器设置 90 advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.211.55.10/24 } track_script { check_nginx } } EOF vim /etc/keepalived/check_nginx.sh count=$(ps -ef |grep nginx |egrep -cv "grep|$$" ) if [ "$count " -eq 0 ];then exit 1 else exit 0 fi chmod +x /etc/keepalived/check_nginx.sh
设置Keepalived开机自启并启动
1 2 3 systemctl enable keepalived systemctl start keepalived systemctl status keepalived
修改Node连接VIP 修改所有node节点上Kubernetes的bootstrap.kubeconfig、kubelet.kubeconfig和kube-proxy.kubeconfig配置文件中的server字段的IP和Port信息,IP替换为VIP、Port替换为Nginx中配置的监听端口,然后重启kubelet和kube-proxy服务
1 2 3 4 5 6 sed -i "s/10.211.55.4:6443/10.211.55.10:8443/g" /opt/kubernetes/cfg/* systemctl restart kubelet systemctl restart kube-proxy #确认node节点是否处于Ready状态 kubectl get nodes
测试VIP是否正常工作 在任意节点上执行以下命令调用API看是否可以正常查看版本信息。其中token替换为token.csv中的token值,IP替换为VIP,Port替换为Nginx中配置的监听端口
如果VIP可以正常工作,可以尝试关闭其中一台Nginx,确认VIP是否可以正常漂移到backup节点,然后再次测试调用API是否正常,验证是否可以达到故障切换的效果
1 2 3 4 5 6 7 8 9 10 11 12 13 curl -k --header "Authorization: Bearer 65cc0bcbe77f4877f288e5604529f384" https://10.211.55.10:8443/version { "major" : "1" , "minor" : "16" , "gitVersion" : "v1.16.4" , "gitCommit" : "224be7bdce5a9dd0c2fd0d46b83865648e2fe0ba" , "gitTreeState" : "clean" , "buildDate" : "2019-12-11T12:37:43Z" , "goVersion" : "go1.12.12" , "compiler" : "gc" , "platform" : "linux/amd64" }
至此一套高可用架构的Kubernetes集群就部署完成了,架构图如下所示。如果还需要再配置kubectl命令自动补全、安装ingress-nginx、安装Helm、配置Kubernetes对接外部存储做持久化存储,比如Ceph,可继续参考后续章节。
配置kubectl命令自动补全 在所有master节点上执行以下操作
1 2 3 4 5 6 7 8 9 yum install bash-completion -y source /usr/share/bash-completion/bash_completionsed -i '$a\source <(kubectl completion bash)' /etc/profile source /etc/profile
安装ingress-nginx 访问Github地址 ,切换到所需版本,找到deploy/static/provider/baremetal/deploy.yaml或者deploy/static/mandatory.yaml资源清单文件,下载并上传到任意一台master节点的/root目录,重命名为ingress.yaml(也可直接将文件内容复制然后在机器上新建文件粘贴,保存为ingress.yaml)
说明
编辑ingress.yaml文件,在Deployment.spec.template.spec中设置启用hostNetwork并添加Service相关配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 ... apiVersion: apps/v1 kind: Deployment metadata: name: nginx-ingress-controller namespace: ingress-nginx labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx spec: replicas: 1 selector: matchLabels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx template: metadata: labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx annotations: prometheus.io/port: "10254" prometheus.io/scrape: "true" spec: hostNetwork: true terminationGracePeriodSeconds: 300 serviceAccountName: nginx-ingress-serviceaccount nodeSelector: kubernetes.io/os: linux ... --- apiVersion: v1 kind: Service metadata: name: ingress-nginx namespace: ingress-nginx spec: type: ClusterIP ports: - name: http port: 80 targetPort: 80 protocol: TCP - name: https port: 443 targetPort: 443 protocol: TCP selector: app.kubernetes.io/name: ingress-nginx
执行以下命令安装ingress-nginx
1 2 cd /root/kubectl apply -f ingress.yaml
确认ingress-nginx的pod创建情况,待所有pod都处于Completed或Running状态后表示ingress-nginx部署完成
1 watch kubectl get pods -n ingress-nginx
验证ingress-nginx
1 2 3 4 5 6 7 8 9 10 11 12 13 14 kubectl create deployment web --image=nginx kubectl expose deployment web --port=80 kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission kubectl create ingress web --class=nginx \ --rule="test.koenli.com/*=web:80" kubectl get pod -o wide -n ingress-nginx | grep ingress-nginx-controller curl --resolve test.koenli.com:80:10.211.55.5 http://test.koenli.com
说明
1 2 3 kubectl delete ingress web kubectl delete service web kubectl delete deployment web
安装Helm
说明 Helm2 与Helm3 两个大版本,两个版本互不兼容,根据Helm与Kubernetes版本兼容情况结合实际业务需求安装其中一个版本即可
Helm2 下载所需版本的Helm安装包(以2.17.0版本为例),上传到所有的master节点的/root/helm目录下(如果没有此目录需先创建),执行以下命令安装Helm客户端
1 2 3 4 cd /root/helm/tar zxf helm-v2.17.0-linux-amd64.tar.gz cd linux-amd64/cp -a helm /usr/local/bin/
创建Tiller授权清单并应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 cat > /root/helm/tiller-rbac.yaml << EOF --- apiVersion: v1 kind: ServiceAccount metadata: name: tiller namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: tiller-cluster-rule roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: tiller namespace: kube-system EOF kubectl apply -f /root/helm/tiller-rbac.yaml
在其中一台master执行以下命令初始化Helm服务端
1 helm init --service-account tiller --skip-refresh
使用命令查看Tiller的pod
1 kubectl get pods -n kube-system |grep tiller
待Running后执行helm version,如果出现如下输出说明Helm的客户端和服务端安装完成。
1 2 Client: &version.Version{SemVer:"v2.17.0" , GitCommit:"a690bad98af45b015bd3da1a41f6218b1a451dbe" , GitTreeState:"clean" } Server: &version.Version{SemVer:"v2.17.0" , GitCommit:"a690bad98af45b015bd3da1a41f6218b1a451dbe" , GitTreeState:"clean" }
说明 STATUS为ImagePullBackOff状态,说明拉取镜像失败,可尝试执行kubectl edit pods tiller-deploy-xxxxxxxx -n kube-system编辑Tiller的deployment,更换所使用的镜像为sapcc/tiller:[tag],此镜像为Mirror of https://gcr.io/kubernetes-helm/tiller/
1 2 3 4 ... image: sapcc/tiller:v2.17.0 ...
保存退出后执行以下命令查看Tiller的pod,待Running后执行helm version确认Helm是否安装完成。
1 kubectl get pods -n kube-system |grep tiller
说明 helm version出现类似如下报错
1 2 Client: &version.Version{SemVer:"v2.17.0" , GitCommit:"a690bad98af45b015bd3da1a41f6218b1a451dbe" , GitTreeState:"clean" } E1213 15:58:40.605638 10274 portforward.go:400] an error occurred forwarding 34583 -> 44134: error forwarding port 44134 to pod 1e92153b279110f9464193c4ea7d6314ac69e70ce60e7319df9443e379b52ed4, uid : unable to do port forwarding: socat not found
解决方法
Helm3 下载所需版本的Helm安装包(以3.14.2版本为例),上传到所有的master节点的/root/helm目录下(如果没有此目录需先创建),执行以下命令安装Helm并验证
1 2 3 4 5 6 7 8 cd /root/helm/tar zxf helm-v3.14.2-linux-amd64.tar.gz cd linux-amd64/cp -a helm /usr/local/bin/helm version
配置rbd-provisioner
说明 Ceph CSI
说明 Ceph官网文档 进行。
Ceph集群和ceph-common安装都完成后,在其中一台master上创建/root/rbd-provisioner目录下,并执行以下命令创建rbd-provisioner所需的yaml文件,标注部分根据实际情况进行修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 mkdir /root/rbd-provisionercd /root/rbd-provisionercat > clusterrole.yaml << EOF kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-provisioner rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] - apiGroups: [""] resources: ["services"] resourceNames: ["kube-dns","coredns"] verbs: ["list", "get"] - apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] EOF cat > clusterrolebinding.yaml << EOF kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-provisioner subjects: - kind: ServiceAccount name: rbd-provisioner namespace: ceph roleRef: kind: ClusterRole name: rbd-provisioner apiGroup: rbac.authorization.k8s.io EOF cat > deployment.yaml << EOF apiVersion: apps/v1 kind: Deployment metadata: name: rbd-provisioner namespace: ceph spec: progressDeadlineSeconds: 600 revisionHistoryLimit: 10 replicas: 1 selector: matchLabels: app: rbd-provisioner strategy: type: Recreate template: metadata: labels: app: rbd-provisioner spec: containers: - name: rbd-provisioner imagePullPolicy: IfNotPresent image: "quay.io/external_storage/rbd-provisioner:latest" env: - name: PROVISIONER_NAME value: ceph.com/rbd serviceAccount: rbd-provisioner restartPolicy: Always EOF cat > role.yaml << EOF apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: rbd-provisioner namespace: ceph rules: - apiGroups: [""] resources: ["secrets"] verbs: ["get"] - apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] EOF cat > rolebinding.yaml << EOF apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: rbd-provisioner namespace: ceph roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: rbd-provisioner subjects: - kind: ServiceAccount name: rbd-provisioner namespace: ceph EOF cat > serviceaccount.yaml << EOF apiVersion: v1 kind: ServiceAccount metadata: name: rbd-provisioner namespace: ceph EOF cat > storageclass.yaml << EOF kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: annotations: storageclass.beta.kubernetes.io/is-default-class: "true" name: rbd provisioner: ceph.com/rbd parameters: monitors: 10.211.55.4:6789,10.211.55.5:6789,10.211.55.6:6789 # 配置Ceph集群的monitor节点信息 pool: k8s # 配置要连接的pool,若没有需要先在ceph集群上创建 adminId: admin adminSecretNamespace: ceph adminSecretName: ceph-secret fsType: ext4 userId: admin userSecretNamespace: ceph userSecretName: ceph-secret imageFormat: "2" imageFeatures: layering reclaimPolicy: Delete volumeBindingMode: Immediate EOF cat > secrets.yaml << EOF apiVersion: v1 kind: Secret metadata: name: ceph-secret namespace: ceph type: "kubernetes.io/rbd" data: # ceph auth add client.kube mon 'allow r' osd 'allow rwx pool=kube' # ceph auth get-key client.admin | base64 key: QVFEcTN5VmRvK28xRHhBQUlKNW5zQ0xwcTd3N0Q5OTJENm9YeGc9PQ== # 配置Ceph集群的kering,此处填的是经过base64编码后的值 EOF
执行以下命令应用
1 2 3 4 cd /root/rbd-provisionerkubectl create namespace ceph kubectl apply -f storageclass.yaml -f clusterrolebinding.yaml -f clusterrole.yaml -f deployment.yaml -f rolebinding.yaml -f role.yaml -f secrets.yaml -f serviceaccount.yaml kubectl get pods -n ceph | grep rbd-provisioner
配置cephfs-provisioner
说明 Ceph CSI
说明 Ceph官网文档 进行。
Ceph集群和ceph-common安装都完成后,在其中一台master上创建/root/cephfs-provisioner目录下,并执行以下命令创建cephfs-provisioner所需的yaml文件,标注部分根据实际情况进行修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 mkdir /root/cephfs-provisionercd /root/cephfs-provisionercat > clusterrole.yaml << EOF kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cephfs-provisioner namespace: ceph rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] - apiGroups: [""] resources: ["services"] resourceNames: ["kube-dns","coredns"] verbs: ["list", "get"] EOF cat > clusterrolebinding.yaml << EOF kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cephfs-provisioner subjects: - kind: ServiceAccount name: cephfs-provisioner namespace: ceph roleRef: kind: ClusterRole name: cephfs-provisioner apiGroup: rbac.authorization.k8s.io EOF cat > deployment.yaml << EOF apiVersion: apps/v1 kind: Deployment metadata: name: cephfs-provisioner namespace: ceph spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: cephfs-provisioner strategy: type: Recreate template: metadata: labels: app: cephfs-provisioner spec: containers: - name: cephfs-provisioner image: "quay.io/external_storage/cephfs-provisioner:latest" imagePullPolicy: IfNotPresent env: - name: PROVISIONER_NAME value: ceph.com/cephfs - name: PROVISIONER_SECRET_NAMESPACE value: ceph command: - "/usr/local/bin/cephfs-provisioner" args: - "-id=cephfs-provisioner-1" - "-disable-ceph-namespace-isolation=true" - "-enable-quota=true" serviceAccount: cephfs-provisioner restartPolicy: Always terminationGracePeriodSeconds: 30 EOF cat > role.yaml << EOF apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: cephfs-provisioner namespace: ceph rules: - apiGroups: [""] resources: ["secrets"] verbs: ["create", "get", "delete"] - apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] EOF cat > rolebinding.yaml << EOF apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: cephfs-provisioner namespace: ceph roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: cephfs-provisioner subjects: - kind: ServiceAccount name: cephfs-provisioner EOF cat > serviceaccount.yaml << EOF apiVersion: v1 kind: ServiceAccount metadata: name: cephfs-provisioner namespace: ceph EOF cat > storageclass.yaml << EOF kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: cephfs provisioner: ceph.com/cephfs parameters: monitors: 10.211.55.4:6789,10.211.55.5:6789,10.211.55.6:6789 # 配置Ceph集群的monitor节点信息 adminId: admin adminSecretName: ceph-secret adminSecretNamespace: "ceph" reclaimPolicy: Delete volumeBindingMode: Immediate EOF
执行以下命令应用
1 2 3 cd /root/cephfs-provisionerkubectl apply -f storageclass.yaml -f clusterrolebinding.yaml -f clusterrole.yaml -f deployment.yaml -f rolebinding.yaml -f role.yaml -f serviceaccount.yaml kubectl get pods -n ceph | grep cephfs-provisioner
参考文档