Flask——数据库
数据库按照一定规则保存程序数据,程序再发起查询取回所需的数据。Web程序最常用基于关系模型的数据库,这种数据库也称为SQL数据库,因为它们使用结构化查询语句。不过最近几年文档数据库和键值对数据库成了流行的替代选择,这两种数据库合称NoSQL数据库。
SQL数据库
关系型数据库把数据存储在表中,表模拟程序中不同的实体。例如,订单管理程序的数据库中可能有表customers、products和orders。
表的列数是固定的,行数是可变的。列定义表所表示的实体的数据属性。例如,customers表中可能有name、address、phone表列。表中的行定义各列对应的真实数据。
表中有个特殊的列,称为主键,其值为表中各行的唯一标识符。表中还可以有称为外键的列,引用同一个表或不同表中某行的主键。行之间的这种联系称为关系,这是关系型数据库模型的基础。图1展示了一个简单数据库的关系图。这个数据库中有两个表,分别存储用户和用户角色。连接两个表的线代表两个表之间的关系。
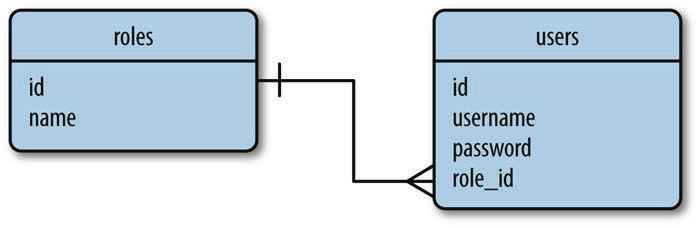
图1 关系型数据库示例
在这个数据库关系图中,roles表存储所有可用的用户角色,每个角色都使用一个唯一的id值(即表的主键)进行标识。users表包含用户列表,每个用户也有唯一的id值。除了id主键之外,roles表中还有name列,users表中还有username列和password列。users表中的role_id列是外键,引用角色的id,通过这种方式为每个指定角色。
从这个例子可以看出,关系型数据库存储数据很高效,而且避免了重复。将这个数据库中的用户角色重命名也很简单,因为角色名只出现在一个地方。一旦在roles表中修改完角色名,所有通过role_id引用这个角色的用户都能立即看到更新。
但从另一方面来看,把数据分别存放在多个表中还是很复杂的。生成一个包含角色的用户列表会遇到一个小问题,因为在此之前要分别从两个表中读取用户和用户角色,再将其联结起来。关系型数据库引擎为联结操作提供了必要的支持。
NoSQL数据库
所有不遵循上节所述的关系模型的数据库统称为NoSQL数据库。NoSQL数据库一般使用集合代替表,使用文档代替记录。NoSQL数据库采用的设计方式使联结变得困难,所以大多数数据库根本不支持这种操作。对于结构如图1所示的关系型数据库,若要列出各用户及其角色,就需要在程序中执行联结操作,即先读取每个用户的role_id,再在roles表中搜索对应的记录。
NoSQL数据库更适合设计成如图2所示的结构。这是执行反规范化操作得到的结果,它减少了表的数量,却增加了数据重复量。
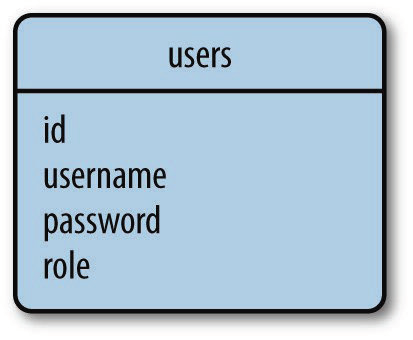
图2 NoSQL数据库示例
这种结构的数据库要把角色名存储在每个用户中。如此一来,将角色重命名的操作就变得很耗时,可能需要更新大量文档。
使用NoSQL数据库当然也有好处。数据重复可以提升查询速度。列出用户及其角色的操作很简答,因为无需联结。
使用SQL还是NoSQL
SQL数据库擅长于用高效且紧凑的形式存储结构化数据。这种数据库需要花费大量精力保证数据的一致性。NoSQL数据库放宽了对这种一致性的要求,从而获得性能上的优势。
对中小型程序来说,SQL和NoSQL数据库都是很好的选择,而且性能相当。
Python数据库框架
大多数的数据库引擎都有对应的Python包,包含开源包和商业包。Flask并不限制你使用何种类型的数据库包,因为可以根据自己的喜好选择使用MySQL、Postgres、SQLite、Redis、MongoDB或者CouchDB。
如果这些都无法满足需求,还有一些数据库抽象层代码包供选择,例如SQLAlchemy和MongoEngine。你可以使用这些抽象包直接处理高等级的Python对象,而不用处理如表、文档或查询语言此类的数据库实例。
选择数据库框架时,你要考虑很多因素。
易用性
如果直接比较数据库引擎和数据库抽象层,显然后者取胜。抽象层,也称为对象关系映射(Object-Relational Mapper,ORM)或对象文档映射(Object-Document Mapper,ODM),在用户不知觉的情况下把高层的面向对象操作转换成低层的数据库指令。
性能
ORM和ODM把对象业务转换成数据库业务会有一定的损耗。大多数情况下,这种性能的降低微不足道,但也不一定都是如此。一般情况下,ORM和ODM对生产率的提升远远超过了这一丁点儿的性能降低,所以性能降低这个理由不足以说服用户完全放弃ORM和ODM。真正的关键点在于如何选择一个能直接操作低层数据库的抽象层,以防特定的操作需要直接使用数据库原生指令优化。
可移植性
选择数据库时,必须考虑其是否能在你的开发平台和生产平台中使用。例如,如果你打算利用云平台托管程序,就要知道这个云服务提供了哪些数据库可供选择。
可移植性还针对ORM和ODM。尽管有些框架只为一种数据库引擎提供抽象层,但其他框架可能做了更高层的抽象,它们支持不同的数据库引擎,而且都使用相同的面向对象接口。SQLAlchemy ORM就是一个很好的例子,它支持很多关系型数据库引擎,包括流行的MySQL,Postgres和SQLite。
Flask集成度
选择框架时,你不一定非得选择已经集成了Flask的框架,但选择这些框架可以节省你编写集成代码的时间。使用集成了Flask的框架可以简化配置和操作,所以专门为Flask开发的扩展是你的首选。
基于以上因素,这里选择使用的数据库框架是Flask-SQLAlchemy(http://flask-sqlalchemy.pocoo.org/2.1/),这个Flask扩展包装了SQLAlchemy((http://www.sqlalchemy.org/)[http://www.sqlalchemy.org/])框架。
使用Flask-SQLAlchemy管理数据库
Flask-SQLAlchemy是一个扩展,简化了在Flask程序中使用SQLAlchemy的操作。SQLAlchemy是一个很强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy提供了高层ORM,也提供了使用数据库原生SQL的低层功能。
和其他大多数扩展一样,Flask-SQLAlchemy也使用pip安装:
1 | (env) [root@server1 myproject]# pip install flask-sqlalchemy |
在Flask-SQLAlchemy中,数据库使用URL指定。最流行的数据库引擎的数据库URL格式如下表所示:
Flask-SQLAlchemy数据库URL
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://username:password@hostname/database |
| Postgres | postgresql://username:password@hostname/database |
| SQLite(Unix) | sqlite:////absolute/path/to/database |
| SQLite(Windows) | sqlite:///c:/absolute/path/to/database |
在这些URL中,hostname表示MySQL服务所在的主机,可以是本地主机(localhost),也可以是远程服务器。数据库服务器上可以托管多个数据库,因此database表示要使用的数据库名。如果数据库需要进行认证,username和password表示数据库用户密令。
说明
SQLite数据库不需要使用服务器,因此不用指定hostname、username和password。URL中的database是硬盘上文件的文件名。
程序使用的数据库URL必须保存到Flask配置对象的SQLALCHEMY_DATABASE_URI键中。配置对象中还有一个很有用的选项,即SQLALCHEMY_COMMIT_ON_TEARDOWN键,将其设为True时,每次请求结束后都会自动提交数据库中的变动。其他配置选项的作用请参阅Flask-SQLAlchemy的文档。下面的run.py展示了如何初始化及配置一个简单的SQLite数据库。
run.py:配置数据库
1 | from flask.ext.sqlalchemy import SQLAlchemy |
db对象是SQLAlchemy类的实例,表示程序使用的数据库,同时还获得了Flask-SQLAlchemy提供的所有功能。
定义模型
模型这个术语表示程序使用的持久化实体。在ORM中,模型一般是一个Python类,类中的属性对应数据库表中的列。
Flask-SQLAlchemy创建的数据库实例为模型提供了一个基类以及一系列辅助类和辅助函数,可用于定义模型的结构。图1中的roles表和users表可定义为模型Role和User。
run.py:定义Role和User模型
1 | class Role(db.Model): |
类变量__tablename__定义在数据库中使用的表明。如果没有定义__tablename__,Flask-SQLAlchemy会使用一个默认名字,但默认的表名没有遵守使用复数形式进行命名的约定,所以最好由我们自己来指定表名。其余的类变量都是该模型的属性,被定义为db.Column类的实例。
db.Column类构造函数的第一个参数是数据库列和模型属性的类型。下面列出了一些可用的列类型以及在模型中使用的Python类型。
最常用的SQLAlchemy列类型
| 类型名 | Python类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 定点数 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 日期 |
| Time | datetime.time | 时间 |
| DateTime | datetime.datetime | 日期和时间 |
| Interval | datetime.timedelta | 时间间隔 |
| Enum | str | 一组字符串 |
| PickleType | 任何Python对象 | 自动使用Pickle序列化 |
| LargeBinary | str | 二进制文件 |
db.Column中其余的参数指定属性的配置选项。
最常使用的SQLAlchemy列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果设为True,这列就是表的主键 |
| unique | 如果设为True,这列不允许出现重复的值 |
| index | 如果设为True,为这列创建索引,提升查询效率 |
| nullable | 如果设为True,这列允许使用空值;如果设为False,这列不允许使用空值 |
| default | 为这列定义默认值 |
说明
Flask-SQLAlchemy要求每个模型都要定义主键,这一列经常命名为id。
虽然没有强制要求,但这两个模型都定义了__repr()__方法,返回一个具有可读性的字符串表示模型,可在调试和测试时使用。
关系
关系型数据库使用关系把不同表中的行联结起来。图1所示的关系图表示用户和角色之间的一种简单关系。这是角色到用户的一对多关系,因为一个角色可属于多个用户,而每个用户都只能有一个角色。
图1中的一对多关系在模型类中的表示方法如下:
1 | class Role(db.Model): |
如图1所示,关系使用users表中的外键连接了两行。添加到User模型中role_id列被定义为外键,就是这个外键建立起了关系。传给db.ForeignKey()的参数’roles.id’表明,这列的值是roles表中行的id值。
添加到Role模型中的users属性代表这个关系的面向对象视角。对于一个Role类的实例,其users属性将返回与角色相关联的用户组成的列表。db.relationship()的第一个参数表明这个关系的另一端是哪个模型。如果模型类尚未定义,可使用字符串形式指定。
db.relationship()中的backref菜蔬向User模型中添加一个role属性,从而定义反向关系。这一属性可替代role_id访问Role模型,此时获取的是模型对象,而不是外键的值。
大多数情况下,db.relationship()都能自行找到关系中的外键,但有时却无法决定把哪一列作为外键。例如,如果User模型中有两个或以上的列定义为Role模型的外键,SQLAlchemy就不知道该使用哪列。如果无法决定外键,你就要为db.relationship()提供额外参数,从而确定所用外键。
常用的SQLAlchemy关系选项
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一个模型中添加反向引用 |
| primaryjoin | 明确指定两个模型之间使用的联结条件。只在模棱两可的关系中需要指定 |
| lazy | 指定如何加载相关记录。可选值有select(首次访问时按需加载)、immediate(源对象加载后就加载)、joined(加载记录,但使用联结)、subquery(立即加载,但使用子查询)、noload(永不加载)和dynamic(不加载记录,但提供加载记录的查询) |
| uselist | 如果设为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字 |
| secondaryjoin | SQLAlchemy无法自行决定时,指定多对多关系中的二级联结条件 |
除了一对多之外,还有几种其他的关系类型。一对一关系可以用前面介绍的一对多关系表示,但调用db.relationship()时要把uselist设为False,把”多”变成”一”。多对一关系也可使用一对多表示,对调两个表即可,或者把外键和db.relationship()都放在”多”这一侧。最复杂的关系类型是多对多,需要用到第三张表,这个表称为关系表。
数据库操作
现在模型已经按照图1所示的数据库关系图完整配置,可以随时使用了。学习如何使用模型的最好方法是在Python shell中实际操作。接下来将介绍最常用的数据库操作
run.py
1 | import os |
创建表
首先,我们要让Flask-SQLAlchemy根据模型类创建数据库。方法是使用db.create_all()函数:
1 | (env) [root@server1 myproject]# python run.py shell |
如果你查看程序目录,会发现新建了一个名为data.sqlite的文件。这个SQLite数据库文件的名字就是在配置中指定的。如果数据库表已经存在于数据库中,那么db.create_all()不会重新创建或者更新这个文件。如果修改模型后要把改动应用到现有的数据库中,这一特性会带来不便。更新现有数据库表的粗暴方式是先删除旧表再重新创建:
1 | db.drop_all() |
遗憾的是,这个方法有个我们不想看到的副作用,它把数据库中原有的数据都销毁了。
插入行
下面这段代码创建了一些角色和用户:
1 | from run import Role,User |
模型的构造函数接受的参数是使用关键字参数指定的模型属性初始值。注意,role属性也可使用,虽然它不是真正的数据库列,但却是一对多关系的高级表示。这些新建对象的id属性并没有明确设定,因为主键是由Flask-SQLAlchemy管理的。现在这些对象只存在于Python中,还未写入数据库。因此id尚未赋值:
1 | print(admin_role.id) |
通过数据库会话管理对数据库所做的改动,在Flask-SQLAlchemy中,会话由db.session表示。准备把对象写入数据库之前,先要将其添加到会话中:
1 | db.session.add(admin_role) |
或者简写成:
1 | db.session.add_all([admin_role,mod_role,user_role,user_john,user_susan,user_david]) |
为了把对象写入数据库,我们要调用commit()方法提交会话:
1 | db.session.commit() |
再次查看id属性,现在它们已经赋值了:
1 | print(admin_role.id) |
说明
数据库会话db.session和Flask——Web表单中介绍的Flask session对象没有关系。数据库会话也称为事务
数据库会话能保证数据库的一致性。提交操作使用原子方式把会话中的对象全部写入数据库。如果在写入会话的过程中发生了错误,整个会话都会失效。如果你始终把相关改动放在会话中提交,就能避免因部分更新导致的数据库不一致性。
说明
数据库会话也可回滚。调用db.session.rollback()后,添加到数据库会话中的所有对象都会还原到它们在数据库时的状态。
修改行
在数据库会话上调用add()方法也能更新模型。我们继续在之前的shell会话中进行操作,下面这个例如把”Admin”角色重命名为”Administrator”:
1 | admin_role.name = 'Administrator' |
删除行
数据库会话还有个delete()方法。下面这个例子把”Moderator”角色从数据库中删除:
1 | db.session.delete(mod_role) |
说明
删除与插入和更新一样,提交数据库会话后才会执行。
查询行
Flask-SQLAlchemy为每个模型类都提供了query对象。最基本的模型查询是取回对应表中的所有记录:
1 | Role.query.all() |
使用过滤器可以配置query对象进行更精确的数据查询。下面这个例子查找角色为”User”的所有用户:
1 | User.query.filter_by(role=user_role).all() |
或者:
1 | User.query.filter_by(role_id=user_role.id).all() |
若要查看SQLAlchemy为查询生成的原生SQL查询语句,只需把query对象转换成字符串:
1 | str(User.query.filter_by(role=user_role)) |
如果你退出了shell会话,前面这些例子中创建的对象就不会以Python对象的形式存在,而是作为各自数据库表中的行。如果你打开了一个新的shell会话,就要从数据库中读取行,再重新创建Python对象。下面这个例子发起了一个查询,加载名为”User”的用户角色:
1 | from run import Role,User |
filter_by()等过滤器在query对象上调用,返回一个更精确的query对象。多个过滤器可以一起调用,直到获得所需结果。
常用的SQLAlchemy查询过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit() | 使用指定的值限制原查询返回的结果数量,返回一个新查询 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
在查询上应用指定的过滤器后,通过调用all()执行查询,以列表的形式返回结果。除了all()之外,还有其他方法能触发查询执行。
最常用的SQLAlchemy查询执行函数
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果没有结果,则返回None |
| first_or_404() | 返回查询的第一个结果,如果没有结果,则终止请求,返回404错误响应 |
| get() | 返回指定主键对应的行,如果没有对应的行,则返回None |
| get_or_404() | 返回指定主键对应的行,如果没找到指定的主键,则终止请求,返回404错误响应 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个Paginate对象,它包含指定范围内的结果 |
关系和查询的处理方式类似。下面这个例子分别从关系的两端查询角色和用户之间的一对多关系:
1 | users = user_role.users |
这个例子中的user_role.users查询有个小问题。执行user_role.users表达式时,隐含的查询会调用all()返回一个用户列表。query对象是隐藏的,因此无法指定更精确的查询过滤器。就这个特定示例而言,返回一个按照字母顺序排序的用户列表可能更好。在之前的示例我们修改了关系的设置,加入了lazy = 'dynamic'参数,从而禁止自动执行查询。
run.py:动态关系
1 | class Role(db.Model): |
这样配置关系之后,user_role.users会返回一个尚未执行的查询,因此可以在其上添加过滤器:
1 | user_role.users.order_by(User.username).all() |
在视图函数中操作数据库
上面介绍的数据库操作可以直接在视图函数中进行,下面展示了首页路由的新版本,已经把用户输入的名字写入了数据库。
run.py:在视图函数中操作数据库
1 | import os |
在这个修改后的版本中,提交表单后,程序会使用filter_by()查询过滤器在数据库中查找提交的名字。变量known被写入用户会话中,因此重定向之后,可以把数据传给模板,用来显示自定义的欢迎信息。注意:要想让程序正常运行,必须按照前面介绍的方法,在Python shell中创建数据库表。
1 | (env) [root@server1 myproject]# python run.py shell |
对应的模板新版本如下,这个模板使用known参数在欢迎消息中加入了第二行,从而对已知用户和新用户显示不同的内容。
templates/base.html
1 | % extends "bootstrap/base.html" %} |
templates/index.html
1 | {% extends "base.html" %} |
集成Python shell
每次启动shell会话都要导入数据库实例和模型,这真是份枯燥的工作。为了避免一直重复导入,我们可以做些配置,让Flask-Script的shell命令自动导入特定的对象。
若想把对象添加导入列表中,我们要为shell命令注册一个make_context()回调函数
1 | from flask.ext.script import Shell |
make_shell_context()函数注册了程序、数据库实例以及模型,因此这些对象能直接导入shell:
1 | (env) [root@server1 myproject]# python run.py shell |
使用Flask-Migrate实现数据库迁移
在开发程序的过程中,你会发现有时需要修改数据库模型,而且修改之后还需要更新数据库。
仅当数据库表不存在时,Flask-SQLAlchemy才会根据模型进行创建。因此,更新表的唯一方式就是先删除旧表,不过这样做会丢失数据库中的所有数据。
更新表的最好方法是使用数据库迁移框架。源码版本控制工具可以跟踪源码文件的变化,类似地,数据库迁移框架能跟踪数据库模式的变化,然后增量式的把变化应用到数据库中。
SQLAlchemy的主力开发人员编写了一个迁移框架,称为Alembic(http://alembic.readthedocs.io/en/latest/index.html)。除了直接使用Alembic之外,Flask程序还可以使用Flask-Migrate(http://flask-migrate.readthedocs.io/en/latest/)扩展。这个扩展对Alembic做了轻量级包装,并集成到Flask-Script中,所有操作都通过Flask-Script命令完成。
创建迁移仓库
首先,我们要在虚拟环境中安装Flask-Migrate:
1 | (env) [root@server1 myproject]# pip install flask-migrate |
这个扩展的初始化方法如下:
1 | from flask.ext.migrate import Migrate, MigrateCommand |
为了导出数据库迁移命令,Flask-Migrate提供了一个MigrateCommand类,可附加到Flask-Script的manager对象上。在这个例子中,MigrateCommand类使用db命令附加。
在维护数据库迁移之前,要使用init子命令创建迁移仓库:
1 | (env) [root@server1 myproject]# python run.py db init |
这个命令会创建migrations文件夹,所有迁移脚本都存放其中。
说明
数据库迁移仓库中的文件要和程序的其他文件一起纳入版本控制。
创建迁移脚本
在Alembic中,数据库迁移用迁移脚本表示。脚本中有两个函数,分别是upgrade()和downgrade()。upgrade()函数把迁移中的改动应用到数据库中,downgrade()函数则将改动删除。Alembic具有添加和删除改动的能力,因此数据库可重设到修改历史的任意一点。
我们可以使用revision命令手动创建Alembic迁移,也可使用migrate命令自动创建。手动创建的迁移只是一个骨架,upgrade()和downgrade()函数都是空的,开发者要使用Alembic提供的Operations对象指令实现具体操作。自动创建的迁移会根据模型定义和数据库当前状态之间的差异生成upgrade()和downgrade()函数的内容。
说明
自动创建的迁移不一定总是正确的,有可能会漏掉一些细节。自动生成迁移脚本后一定要进行检查。
migrate子命令用来自动创建迁移脚本:
1 | (env) [root@server1 myproject]# python run.py db migrate -m "initial migration" |
更新数据库
检查并修正好迁移脚本之后,我们可以使用db upgrade命令把迁移应用到数据库中:
说明
迁移时先删除数据库文件data.splite,然后执行Flask-Migrate提供的upgrade命令,使用这个迁移框架重新生成数据库。
1 | (env) [root@server1 myproject]# python run.py db upgrade |
对第一个迁移来说,其作用和调用db.create_all()方法一样。但在后续的迁移中,upgrade命令能把改动应用到数据库中,且不影响其中保存的数据。
参考书籍
- 《Flask Web开发——基于Python的Web应用开发实战》