Ollama单机多(无)卡部署DeepSeek蒸馏版构建本地知识库
本文介绍通过Ollama部署DeepSeek蒸馏版,并通过FastGPT构建本地知识库的详细步骤,适合个人私有化部署体验。
环境信息
| 配置 | 操作系统 | IP地址 |
|---|---|---|
| 2核8G无GPU卡 | CentOS7.5 | 10.211.55.5 |
安装Ollama
说明
Ollama从0.5.13版本开始,需要较新版本的glibc,但是升级glibc操作复杂,风险较大,因此如果没有特殊要求建议安装0.5.12及以下版本。官方已经有人提了相关issue,看后续是否会有优化
在线安装
1 | yum install pciutils -y |
说明
如果需要安装指定版本,可参考以下命令
1 | yum install pciutils -y |
离线安装
到https://github.com/ollama/ollama/releases下载对应版本的压缩包,上传到/root并执行以下命令解压
1 | cd /root/ |
创建Ollama用户和组
1 | sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama |
创建Service文件
1 | cat > /etc/systemd/system/ollama.service << EOF |
启动Ollama并设置开机自启
1 | sudo systemctl daemon-reload |
配置Ollama环境变量
Ollama默认监听本机地址127.0.0.1,这意味着服务只能在本机访问,如果需要从外部网络访问,可以通过配置Ollama环境变量OLLAMA_HOST为0.0.0.0,让服务监听所有可用的网络接口。以下是一些常用的环境变量配置与解析
| 环境变量 | 功能说明 | 示例 |
|---|---|---|
| OLLAMA_HOST | 设置API服务监听地址与端口,0.0.0.0表示允许所有IP访问 |
0.0.0.0:11434 |
| OLLAMA_ORIGINS | 允许跨域请求的域名列表,*为通配符 |
* |
| OLLAMA_MODELS | 自定义模型存储路径,避免占用系统盘空间 | /usr/share/ollama/ |
| OLLAMA_KEEP_ALIVE | 控制模型在内存中的保留时间,减少重复加载开销 | 24h(24小时) |
| OLLAMA_DEBUG | 启用调试日志,排查服务异常 | 1(开启) |
| OLLAMA_FLASH_ATTENTION | 启用Flash Attention | 1(开启) |
| OLLAMA_NUM_PARALLEL | 并行处理请求数,提升高并发场景下的吞吐量 | 2 |
| OLLAMA_GPU_OVERHEAD | 扩展显存不足时,利用RAM/VRAM混合加载大模型(需手动计算显存值) | 81920000000(80GB) |
1 | mkdir -p /etc/systemd/system/ollama.service.d |
加载DeepSeek大模型
说明
本文以1.5B模型为例,你可以根据自己的硬件资源情况选择加载其他参数量的模型
在线拉取
1 | ollama pull deepseek-r1:1.5b |
离线导入
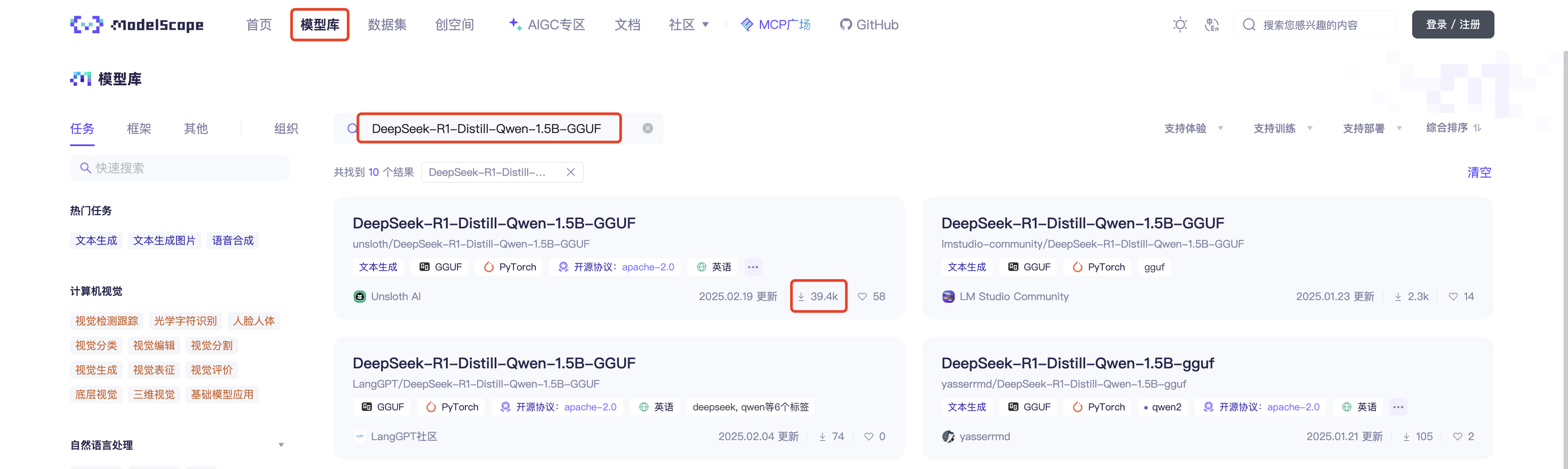
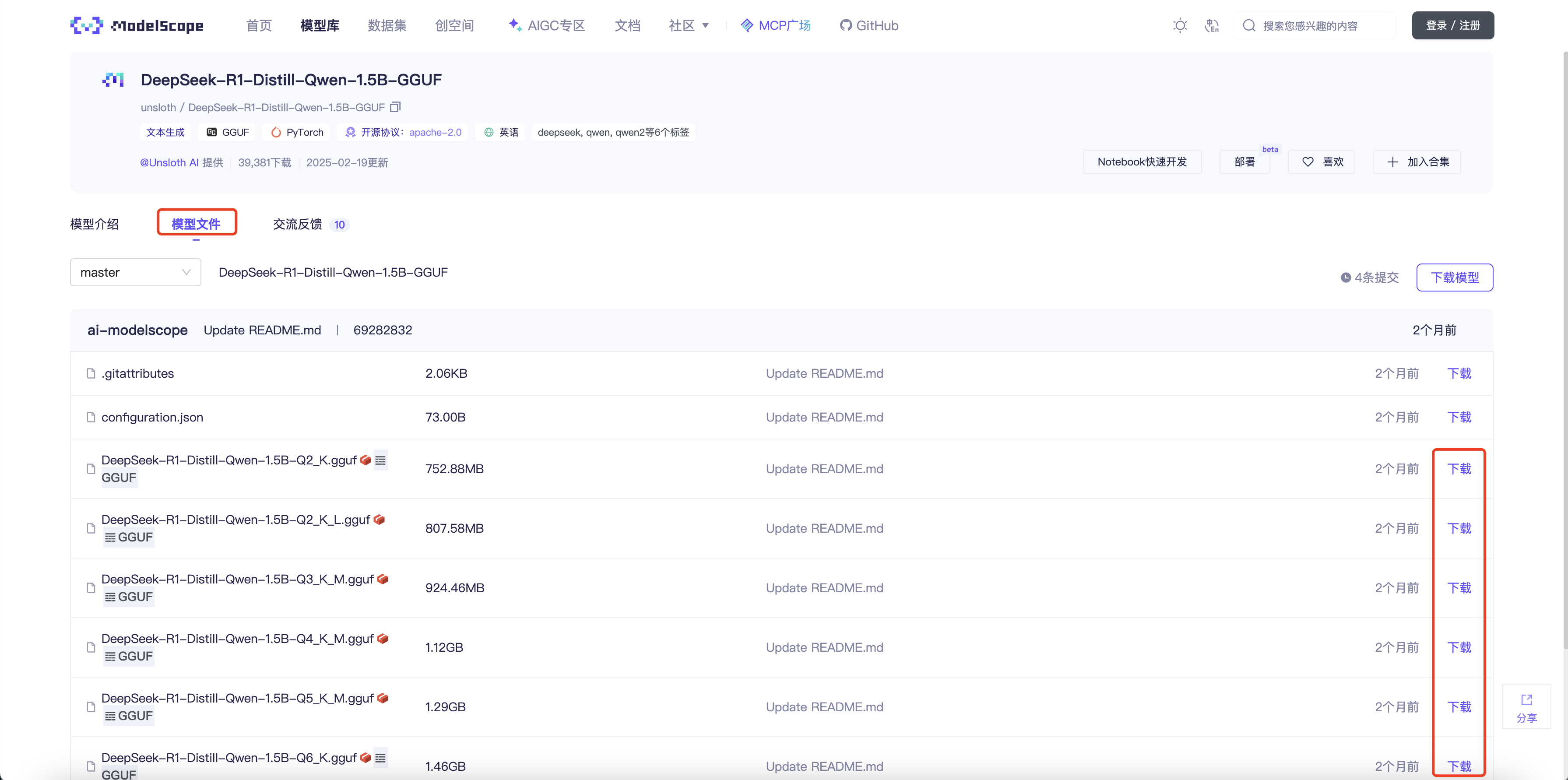
到魔搭社区搜索并下载模型的GGUF文件,上传到/root
创建Modelfile
说明
FROM后面的路径修改为GGUF文件的实际路径
以下Modelfile文件内容是通过ollama show --modelfile deepseek-r1:1.5b查询在线拉取的模型的Modelfile文件内容修改得到的
1 | cat > /root/Modelfile << EOF |
导入模型
1 | ollama create deepseek-r1:1.5b -f /root/Modelfile |
安装Docker
到对应平台的目录下载所需版本的Docker二进制包,并上传到/root目录下(本文以x86平台下的28.0.4为例),然后执行以下命令安装Docker
1 | # 解压并拷贝二进制文件到对应目录下 |
安装Docker Compose
说明
FastGPT建议Docker Compose版本最好在2.17以上
下载所需版本的Docker Compose二进制包,并上传到/root目录下(本文以x86平台下的v2.34.0为例),然后执行以下命令安装Docker Compose
1 | mv docker-compose-linux-x86_64 docker-compose |
安装FastGPT
推荐配置
PgVector版本
非常轻量,适合知识库索引量在5000万以下。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试(可以把计算进程设置少一些) | 2c4g | 2c8g |
| 100w 组向量 | 4c8g 50GB | 4c16g 50GB |
| 500w 组向量 | 8c32g 200GB | 16c64g 200GB |
Milvus版本
对于亿级以上向量性能更优秀。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c8g | 4c16g |
zilliz cloud版本
Zilliz Cloud由Milvus原厂打造,是全托管的SaaS向量数据库服务,性能优于Milvus并提供SLA,点击使用Zilliz Cloud。
由于向量库使用了Cloud,无需占用本地资源,无需太关注。
FastGPT安装
- 项目地址:https://github.com/labring/FastGPT
- 开发与部署指南:https://doc.tryfastgpt.ai/docs/development/docker/
- Release包下载链接:https://github.com/labring/FastGPT/releases
说明
本文介绍的方法会安装操作时的最新版本(本文发表时最新版本为4.9.6),如果你需要安装其他版本可以到https://github.com/labring/FastGPT/releases下载对应版本的源码包进行安装。配置文件config.json在projects/app/data/目录下,各版本docker-compose.yml模板文件在deploy/docker/目录下
创建FastGPT安装目录
1 | cd /root/ |
准备配置文件和对应版本的docker-compose.yml文件
1 | cd FastGPT |
编辑docker-compose.yml文件,将镜像地址修改为阿里云镜像地址
说明
从FastGPT 4.8.23版本开始,引入AI Proxy来进一步方便模型的配置,并且从FastGPT 4.9.0版本开始作为默认的接入方式。
1 | ... |
在docker-compose.yml同级目录下执行以下命令启动容器
1 | docker compose up -d |
通过http://ip:3000直接访问(注意开放防火墙)。登录用户名为root,密码为docker-compose.yml环境变量里设置的DEFAULT_ROOT_PSW,默认为1234。
配置FastGPT
说明
系统至少需要一个语言模型和一个索引模型才能正常使用。
配置语言模型
选择“账号”-“模型提供商”-“模型渠道”,进入渠道配置页面,点击右上角的“新增渠道”
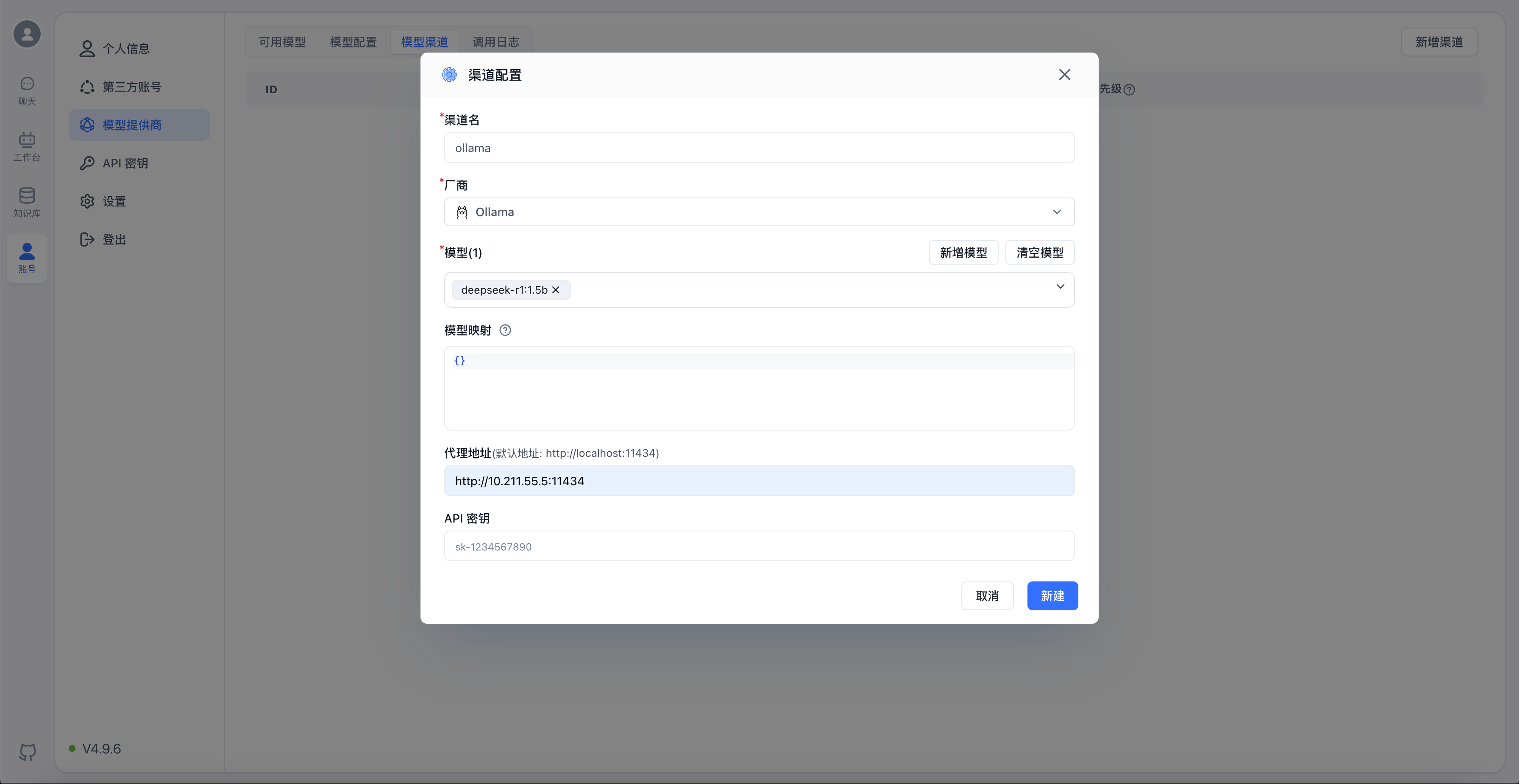
以添加刚刚安装的deepseek-r1:1.5b模型为例,配置如下图
渠道名:展示在外部的渠道名称,仅作标识;
厂商:模型对应的厂商,不同厂商对应不同的默认地址和API密钥格式;
模型:当前渠道具体可以使用的模型,系统内置了主流的一些模型,如果下拉框中没有想要的选项,可以点击“新增模型”,增加自定义模型;
模型映射:将FastGPT请求的模型,映射到具体提供的模型上,详细说明可点击⍰查看;
代理地址:具体请求的地址,系统给每个主流渠道配置了默认的地址,如果无需改动则不用;
API密钥:从模型厂商处获取的API凭证。注意部分厂商需要提供多个密钥组合,可以根据提示进行输入;
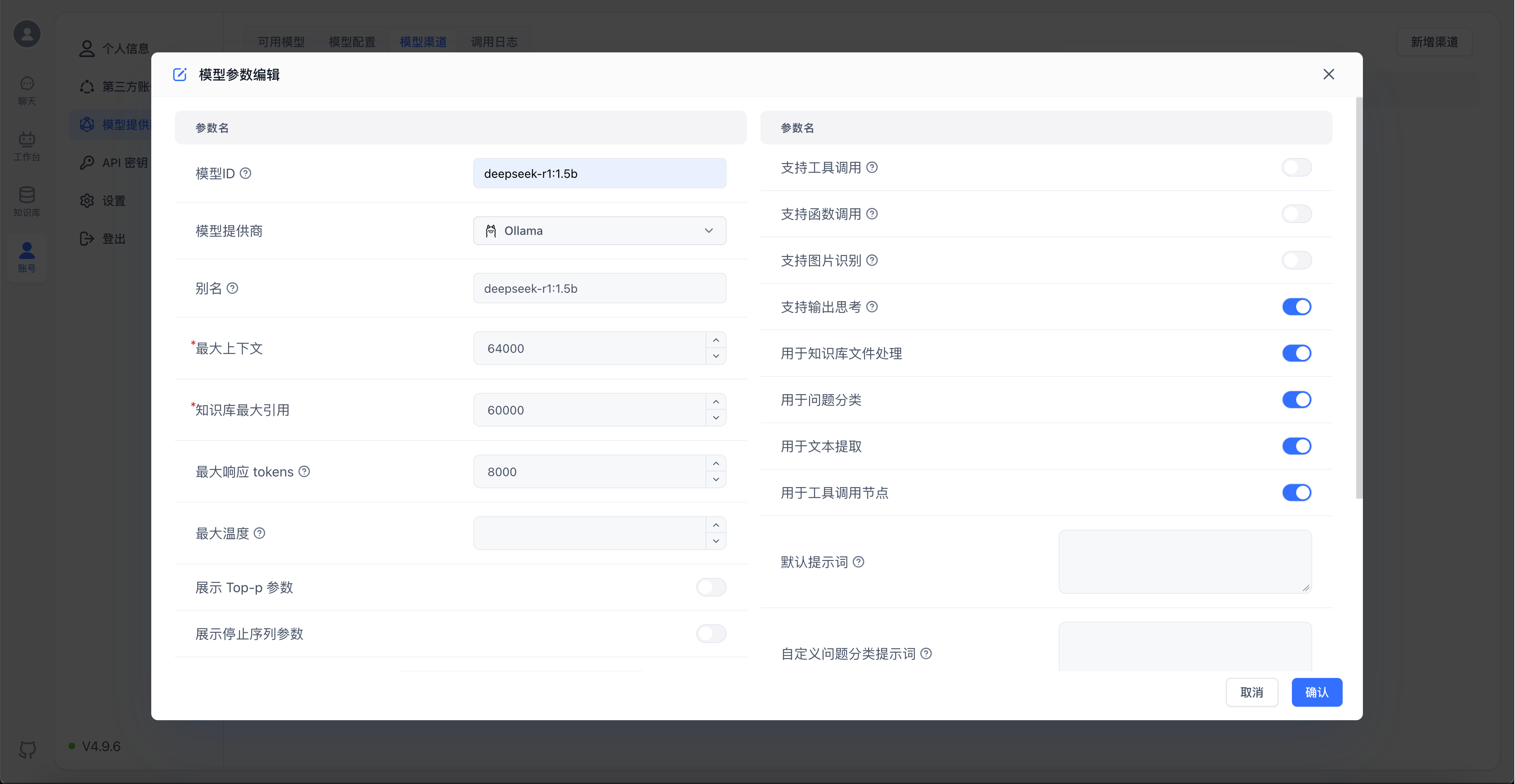
以下为新增deepseek-r1:1.5b自定义模型的配置截图
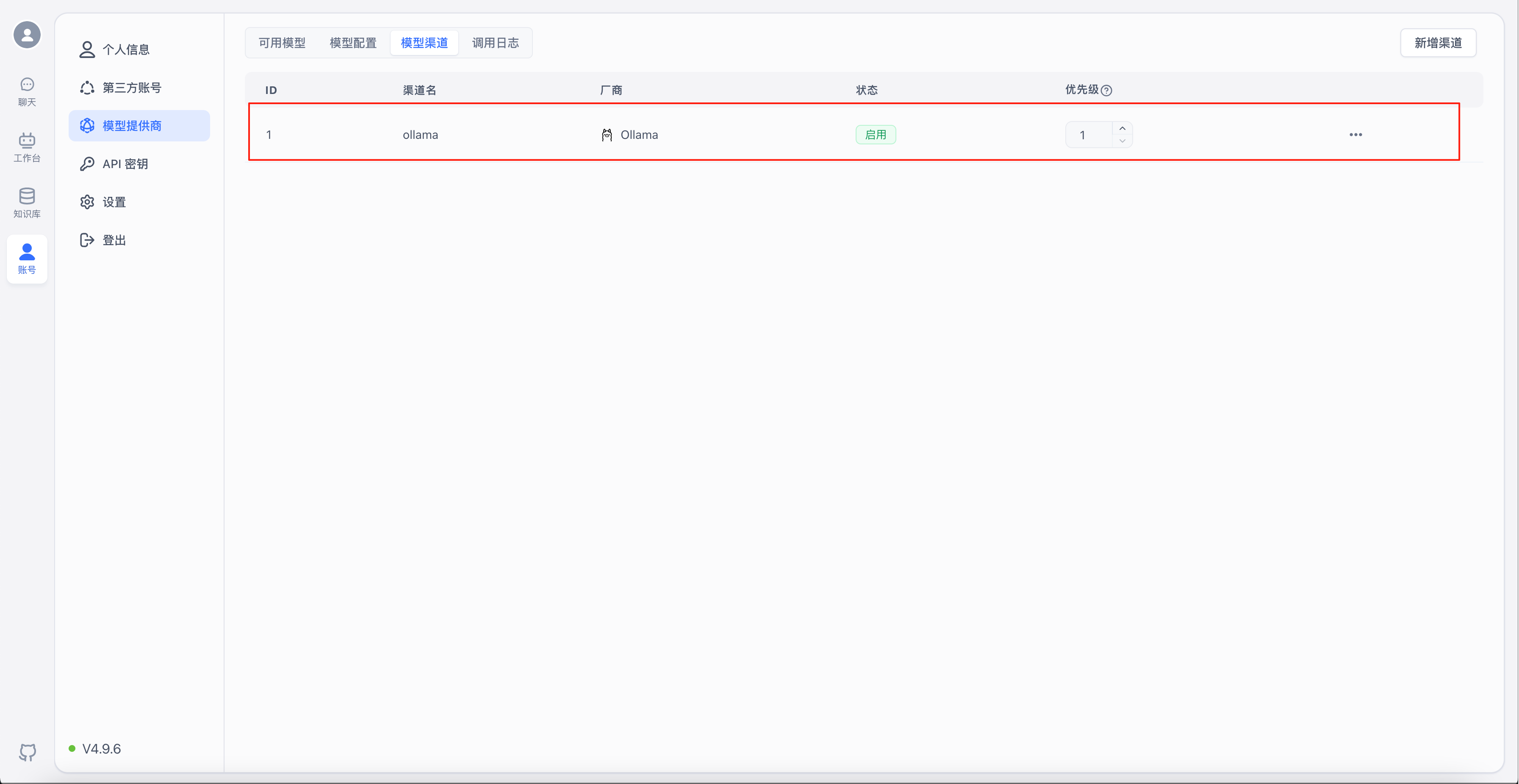
新增完成后就能在“模型渠道”下看到刚刚配置的渠道
点击“...”-“模型测试”,可以对渠道中的所有模型进行批量测试,确保配置的模型有效
测试完成后会输出每个模型的测试结果以及请求时长

部署并配置索引模型
部署索引模型
FastGPT默认使用了openai的embedding向量模型,私有化部署的话,可以使用M3E向量模型进行替换。M3E向量模型属于小模型,资源使用不高,CPU也可以运行。下面教程是基于 “睡大觉” 同学提供的一个镜像。
- 镜像名:stawky/m3e-large-api:latest
- 国内镜像:registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
说明
端口号:6008
环境变量:sk-key默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk,也可以自定义并通过Docker环境变量引入。
执行以下命令运行M3E向量模型
1 | docker run -d --name m3e --restart=always -p 6008:6008 -e sk-key="sk-aaabbbcccdddeeefffggghhhiiijjjkkk" registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api |
测试API接口是否正常
说明
<host>修改为主机IP<sk-key>修改为引入的sk-key值
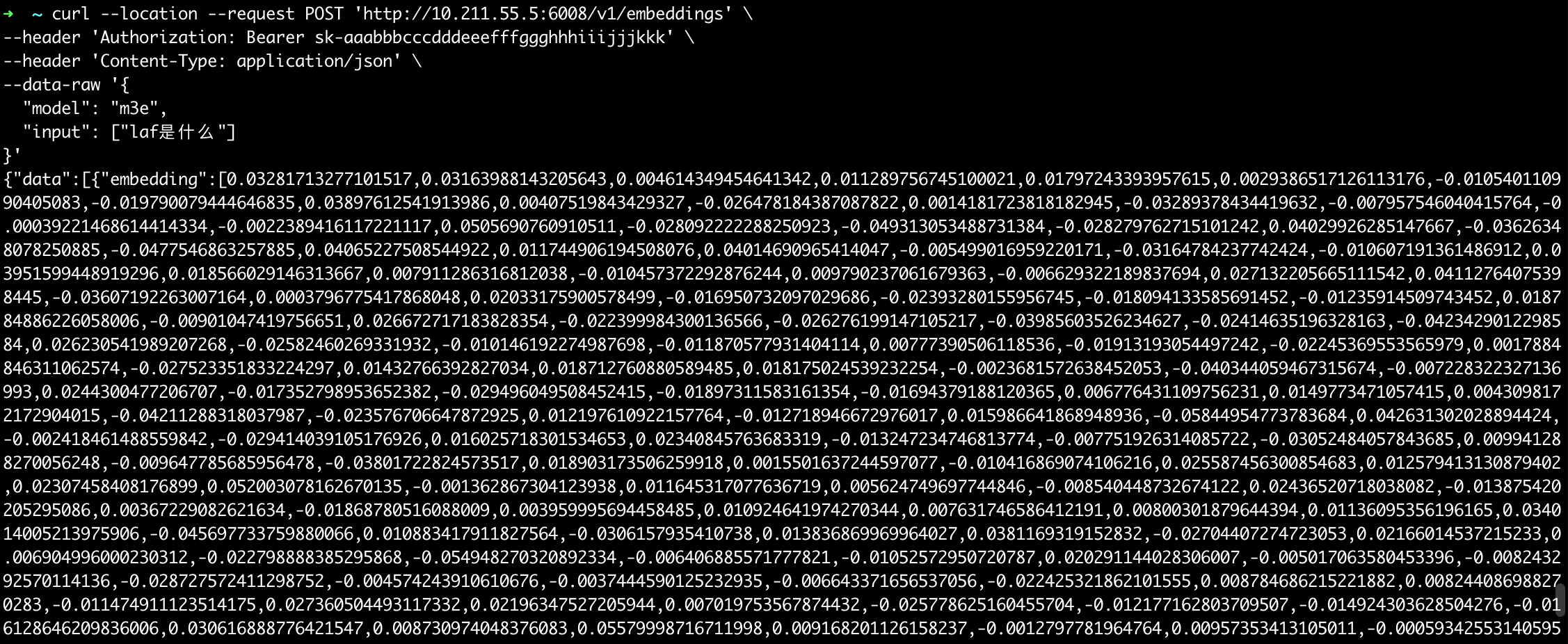
1 | curl --location --request POST 'http://<host>:6008/v1/embeddings' \ |
如果可以出现如下输出,表示M3E向量模型工作正常
配置索引模型
选择“账号”-“模型提供商”-“模型配置”,进入模型配置页面,点击右上角的“新增模型”-“索引模型”
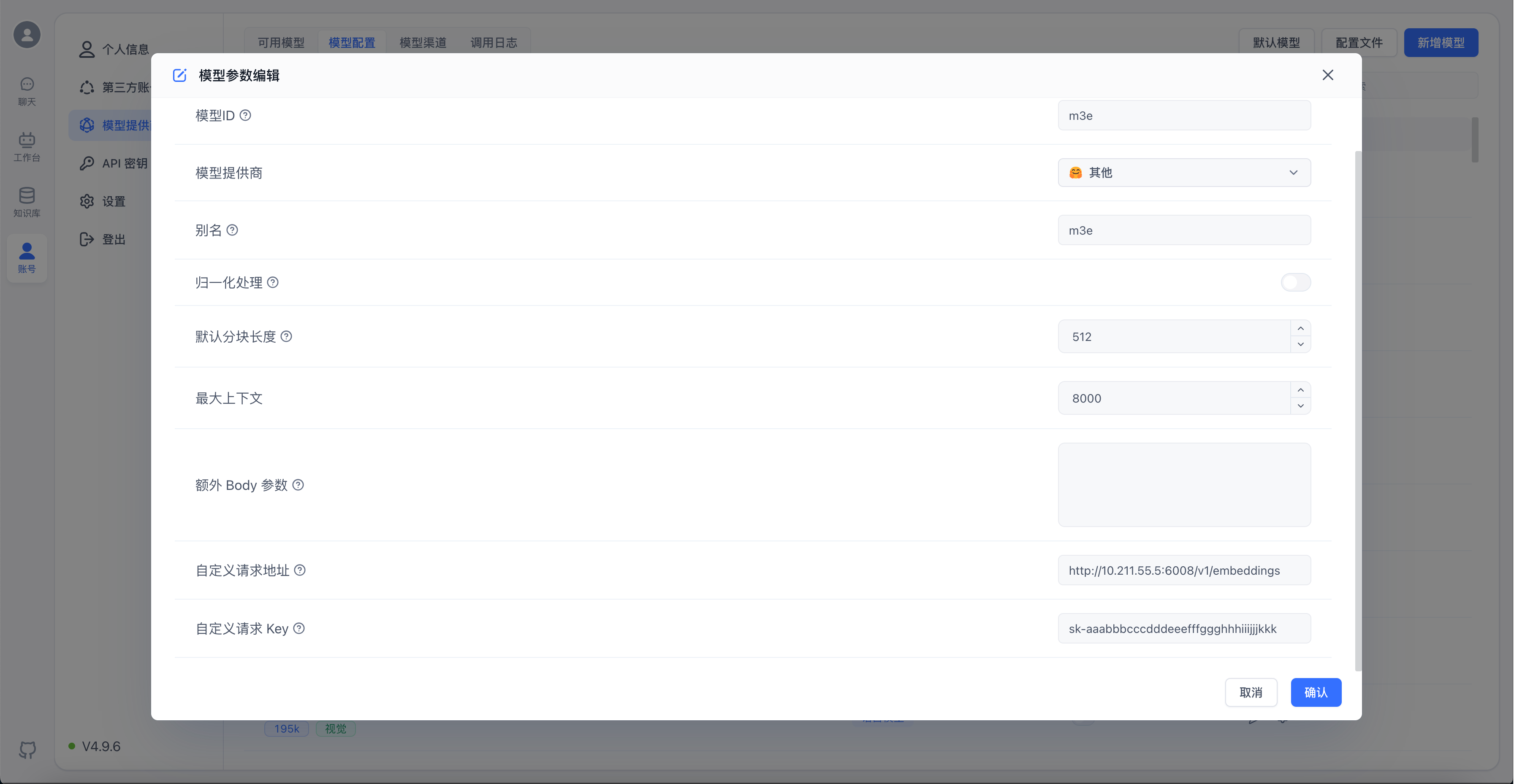
以添加M3E模型为例,配置如下图
说明
自定义请求地址中的/v1/embeddings后缀是必须的
自定义请求Key要与启动模型时的sk-key值对应
添加完成后点击模型右侧的“模型测试”按钮,若测试成功即代表模型可以正常工作
构建本地知识库
创建知识库
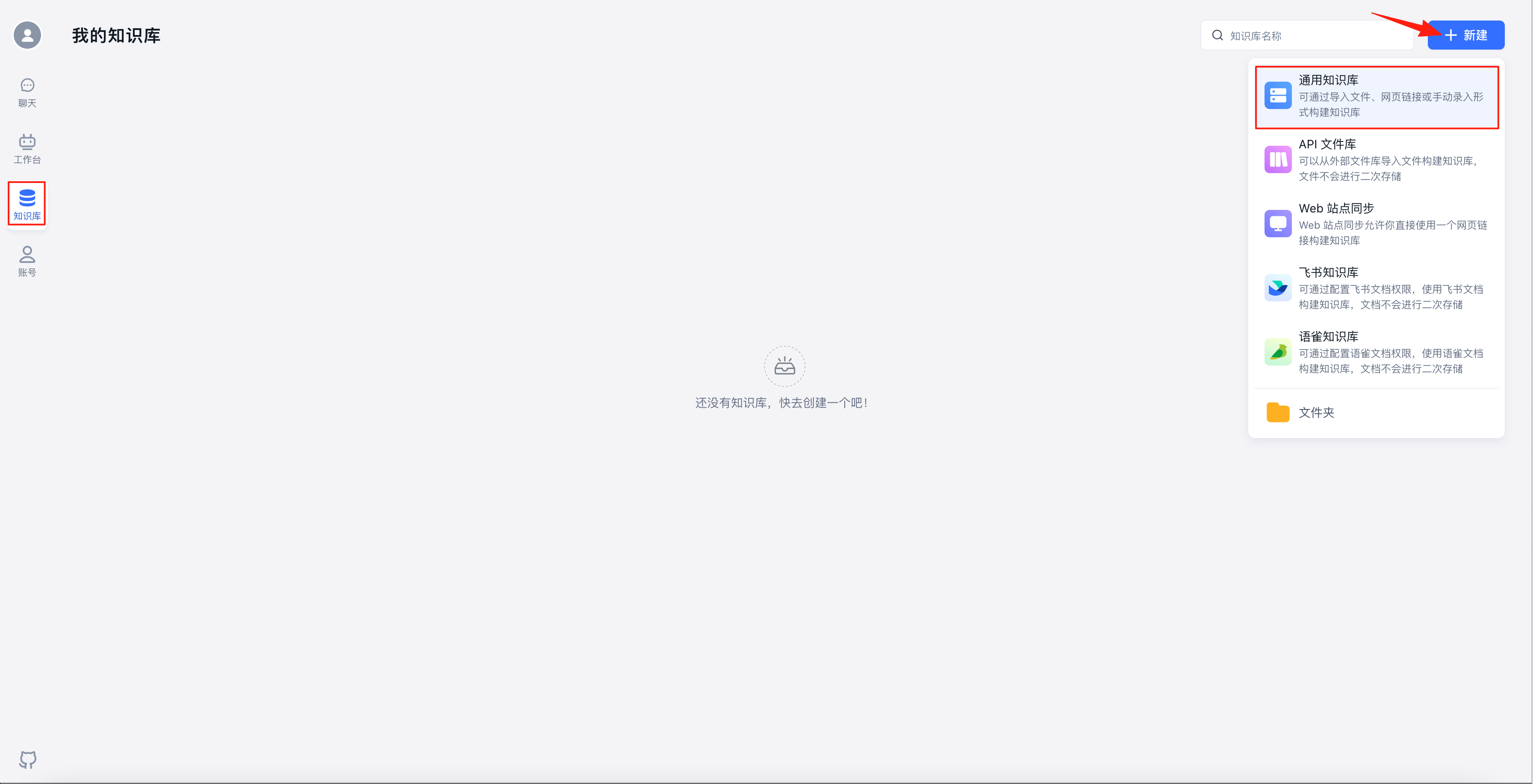
选择“知识库”,点击右上角的“新建”-“通用知识库”
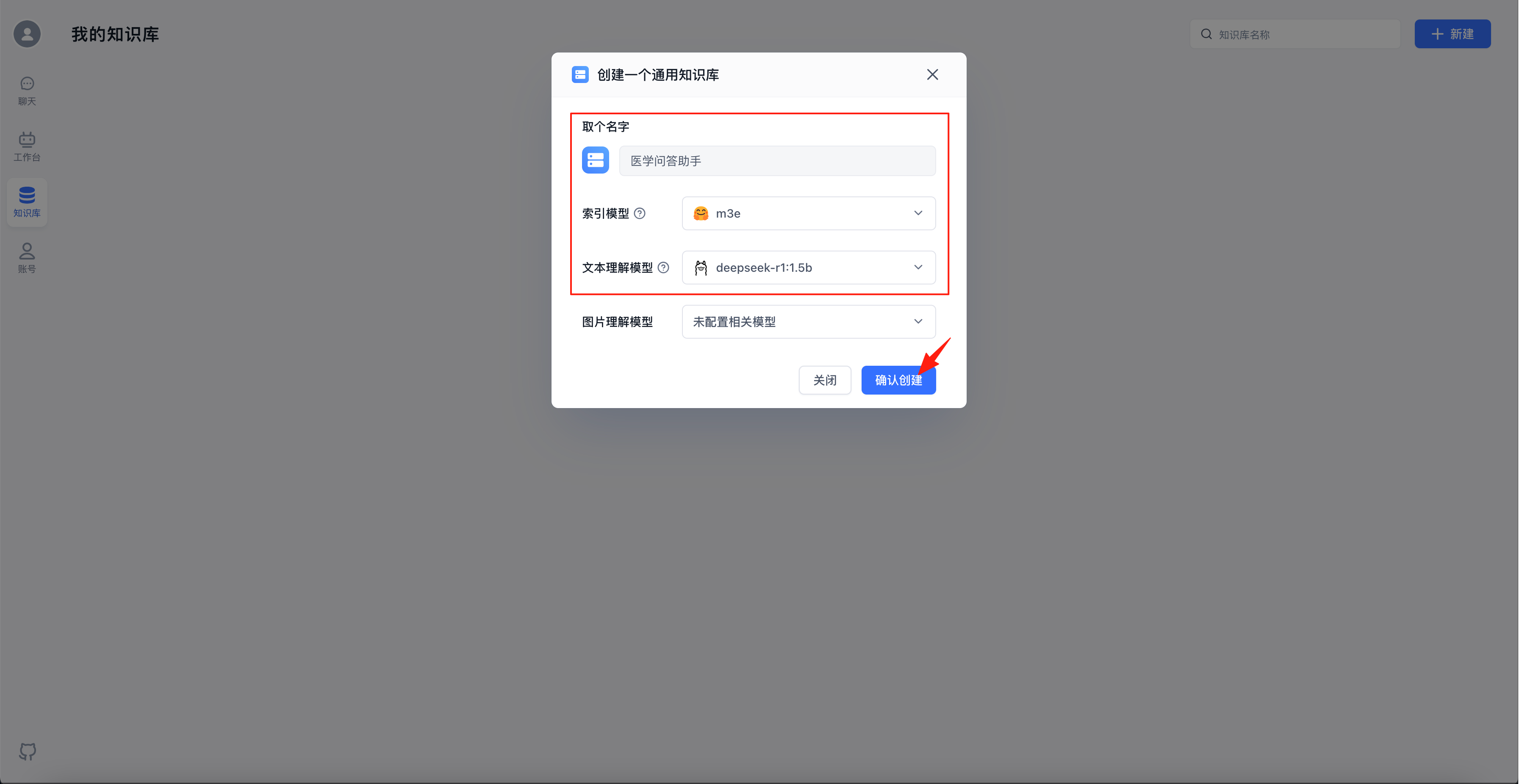
给知识库取个名字,索引模型和文本理解模型选择上面配置的m3e和deepseek-r1:1.5b,点击“确认创建”
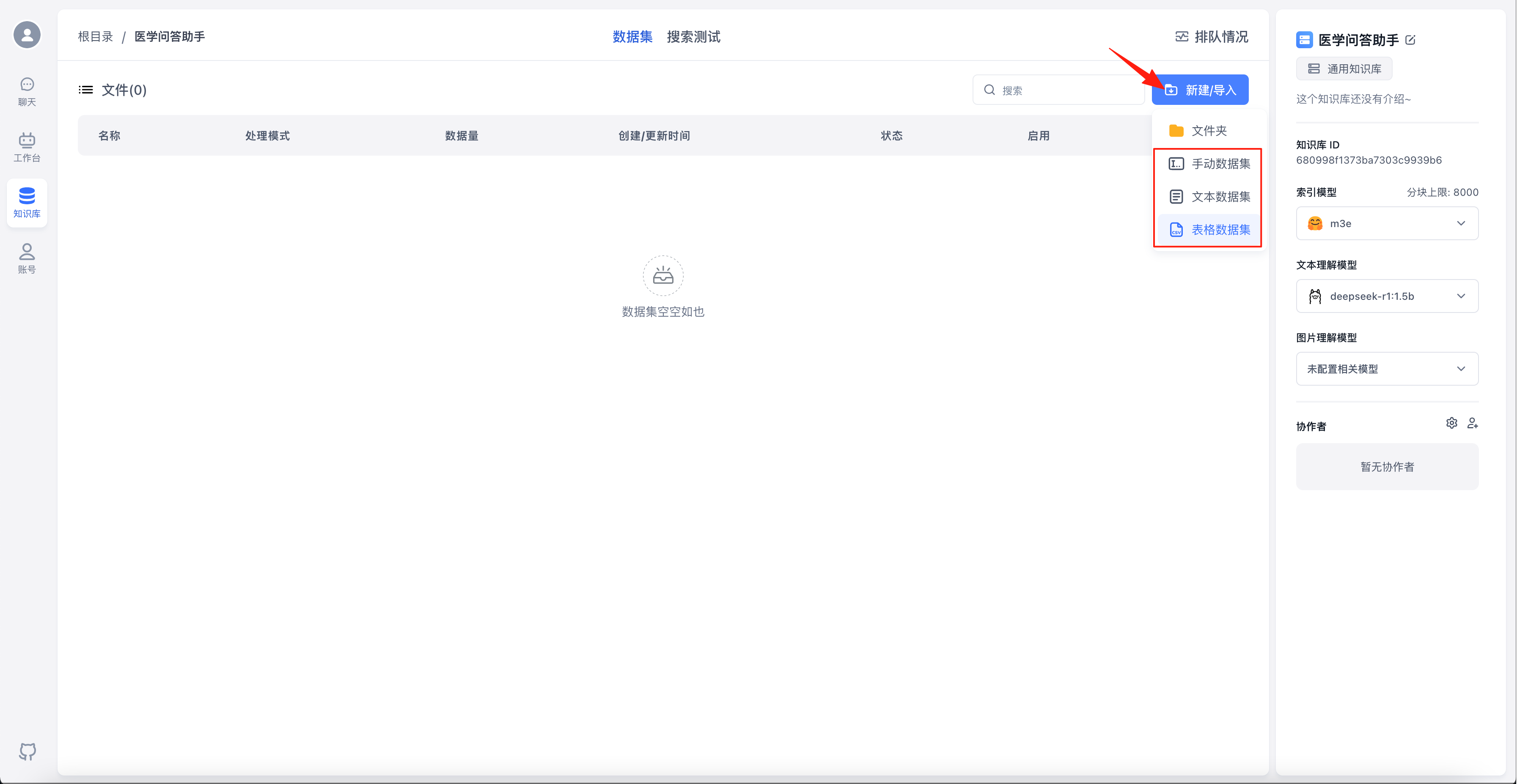
点击“新建/导入”,并根据要导入的数据集类型选择对应菜单(本文导入的数据集为.csv类型文件,故选择“表格数据集”)
说明
PDF、TXT、DOCX等格式的文件、网页链接、自定义文本选择“文本数据集”
CSV类型文件选择“表格数据集”
点击“点击或拖动文件到此处上传”,选择要上传的数据集文件,点击“下一步”
说明
数据集下载地址:https://pan.baidu.com/s/15I9djby1qWNjEENtOQLzKw 提取码:wxf3
本文使用的测试数据集为之前参加技能竞赛试题中提供的,仅供测试使用
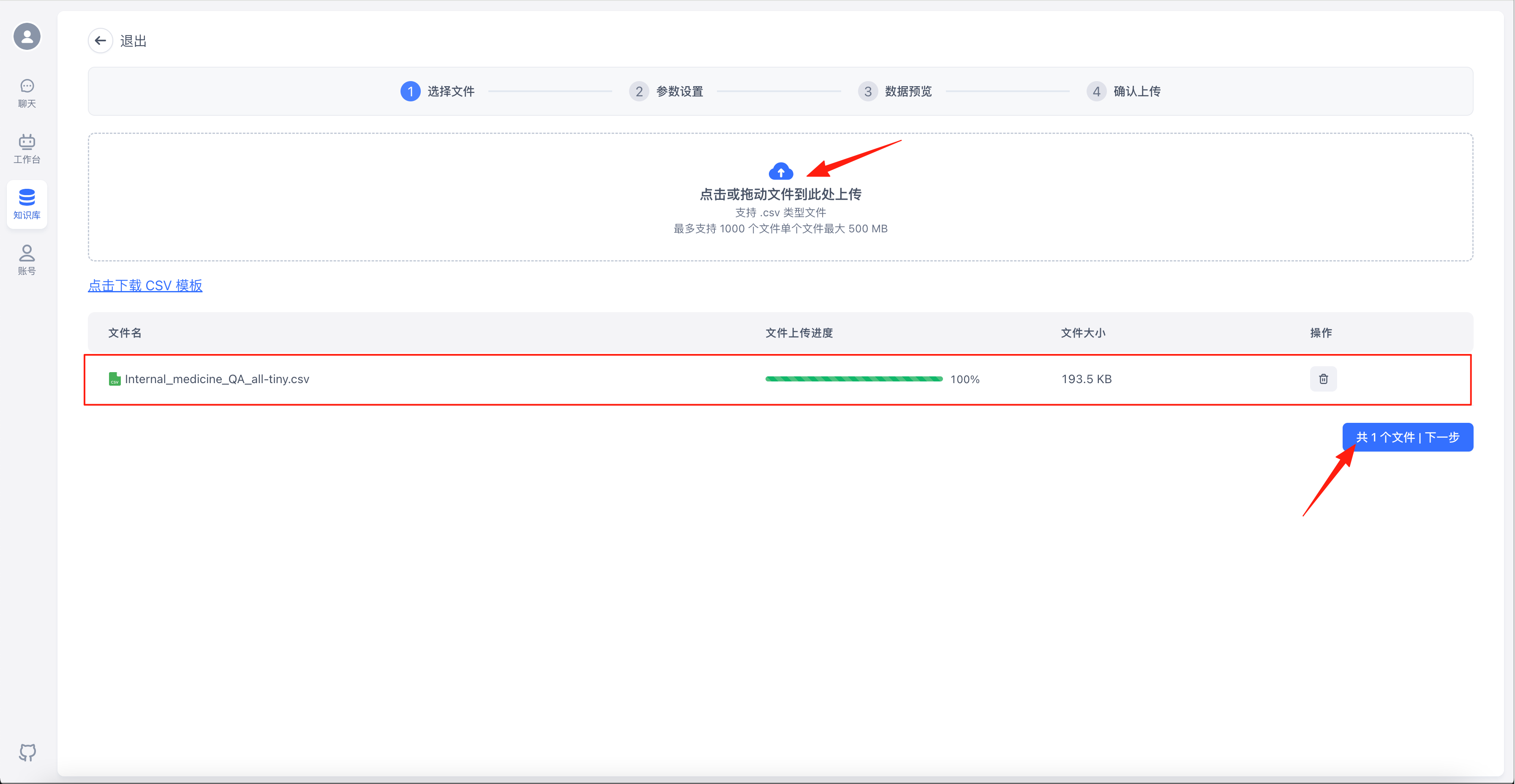
点击左侧文件后可以在右侧进行预览,预览没问题的话点击“下一步”
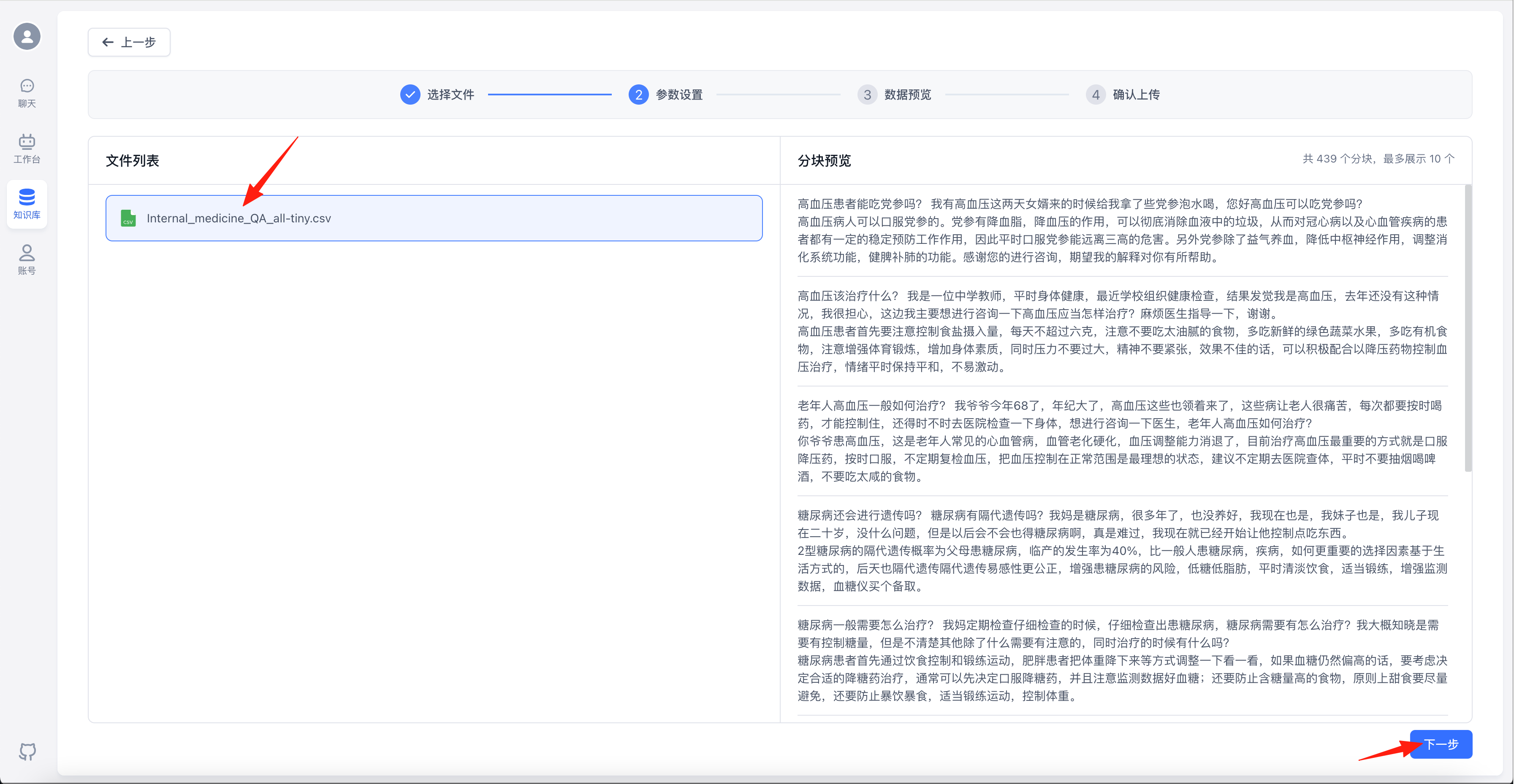
点击“开始上传”
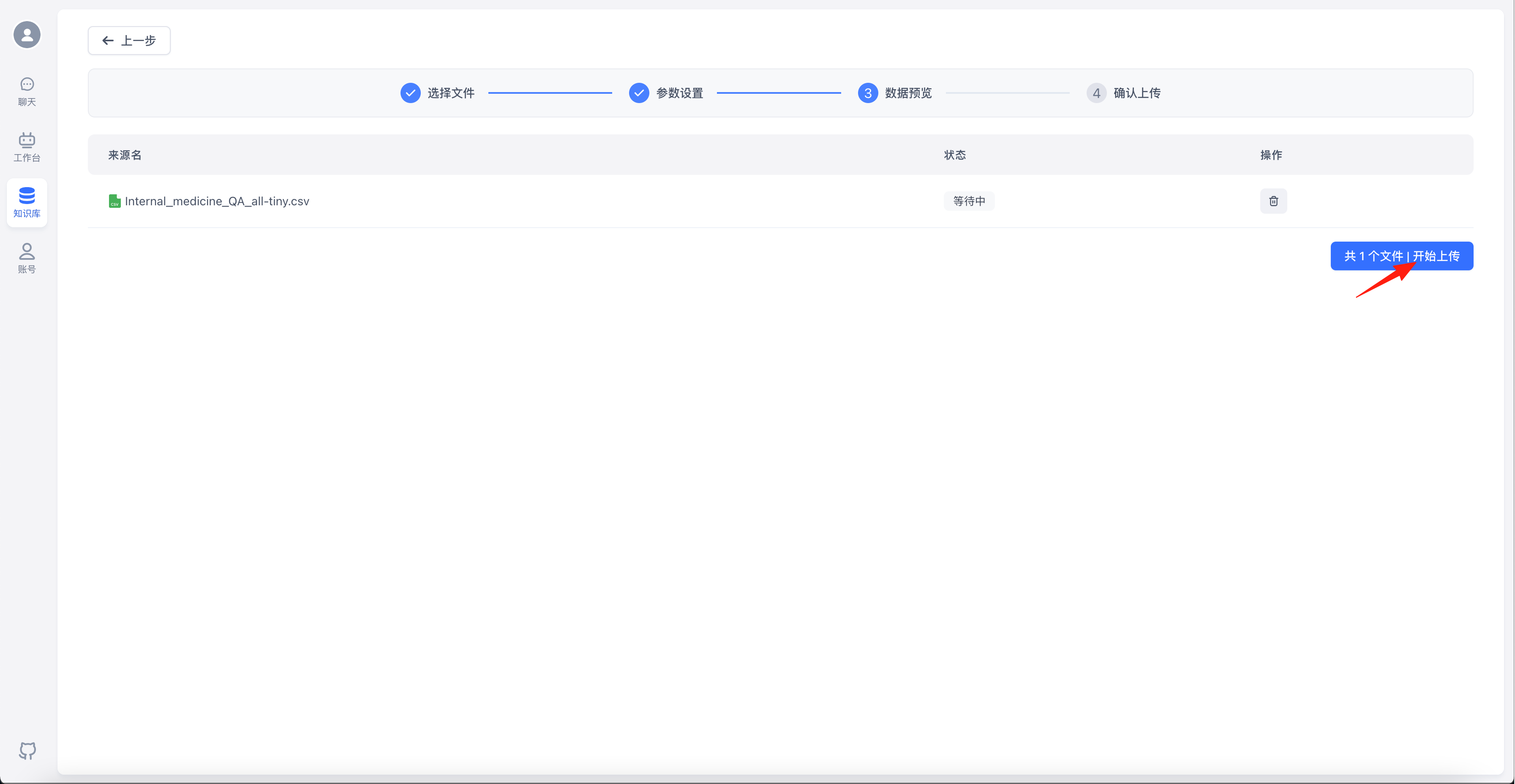
数据集向量化需要时间,耐心等待…待状态变成“已就绪”后,代表向量化完成
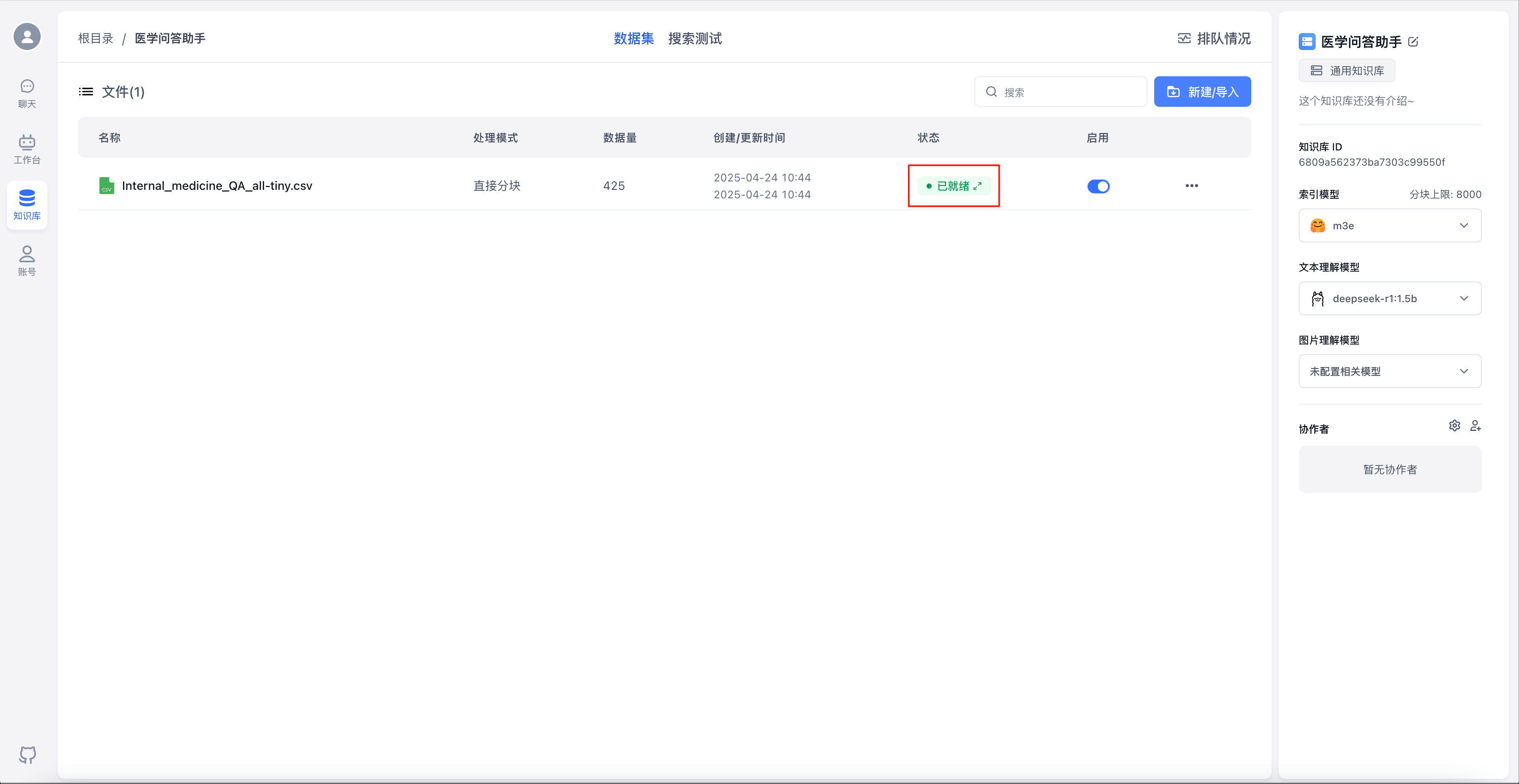
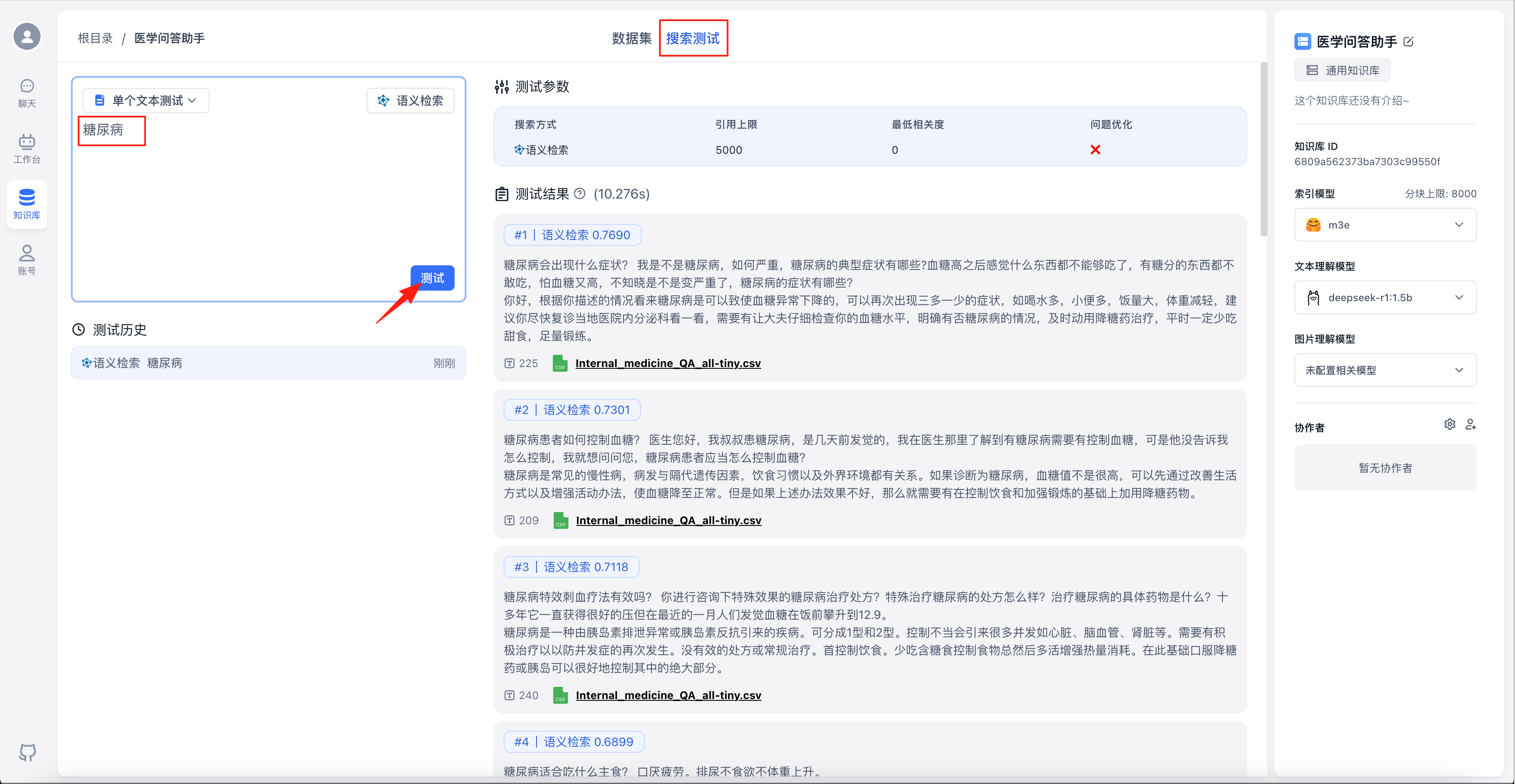
切换到“搜索测试”,输入文本,点击“测试”,可以进行检索测试
创建应用
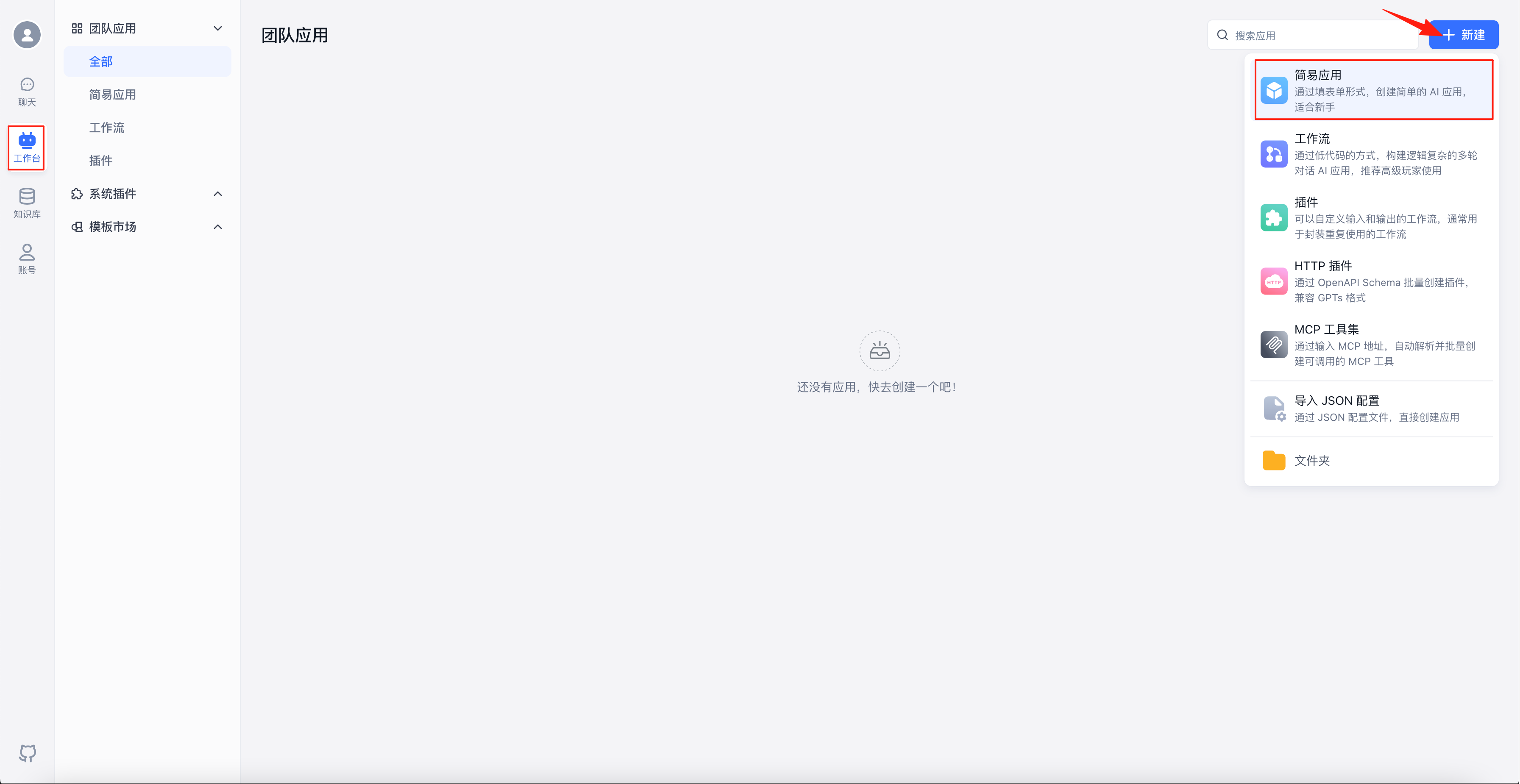
选择“工作台”,点击右上角的“新建”-“简易应用”
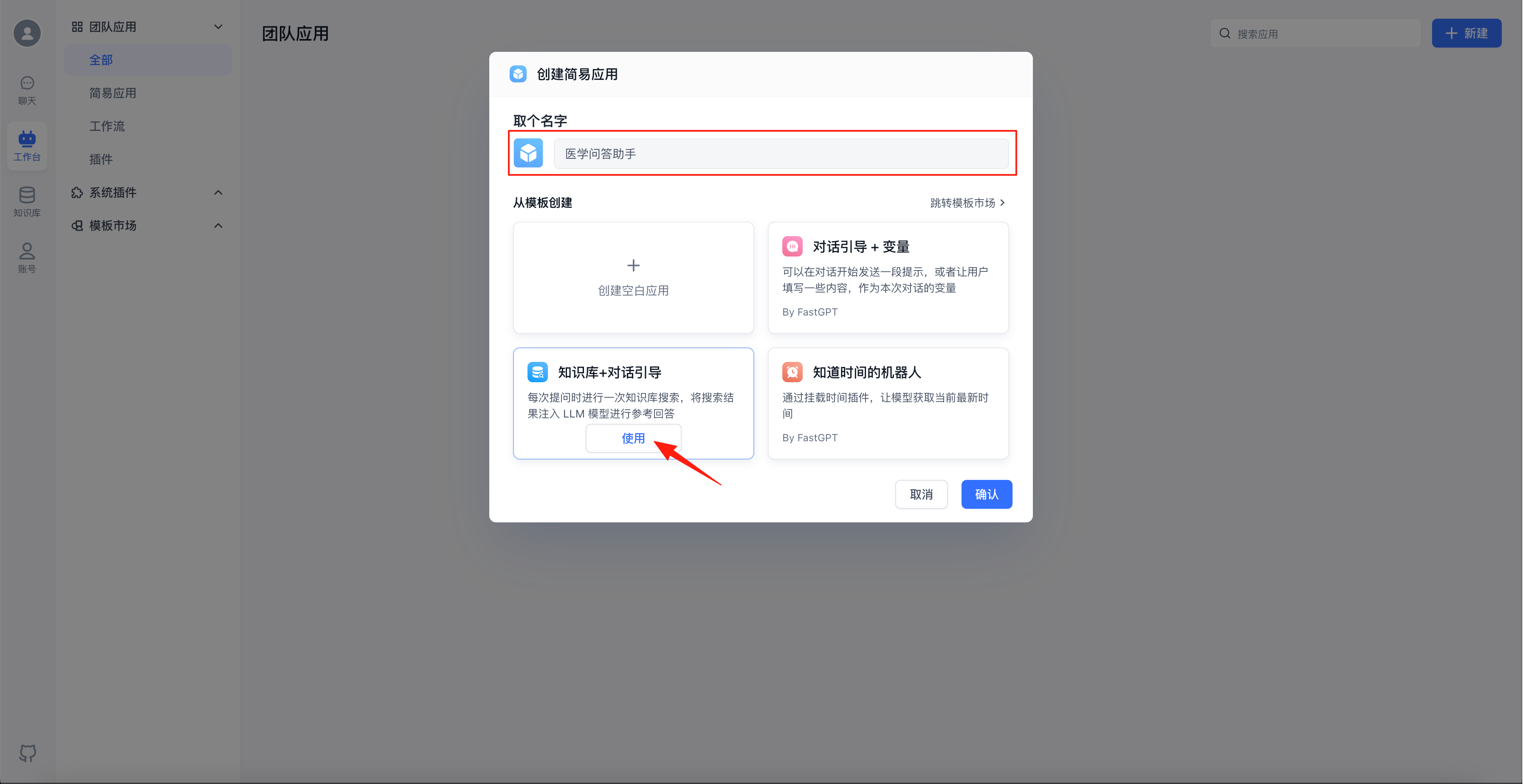
给应用取个名字,模板选择“知识库+对话引导”,点击“使用”
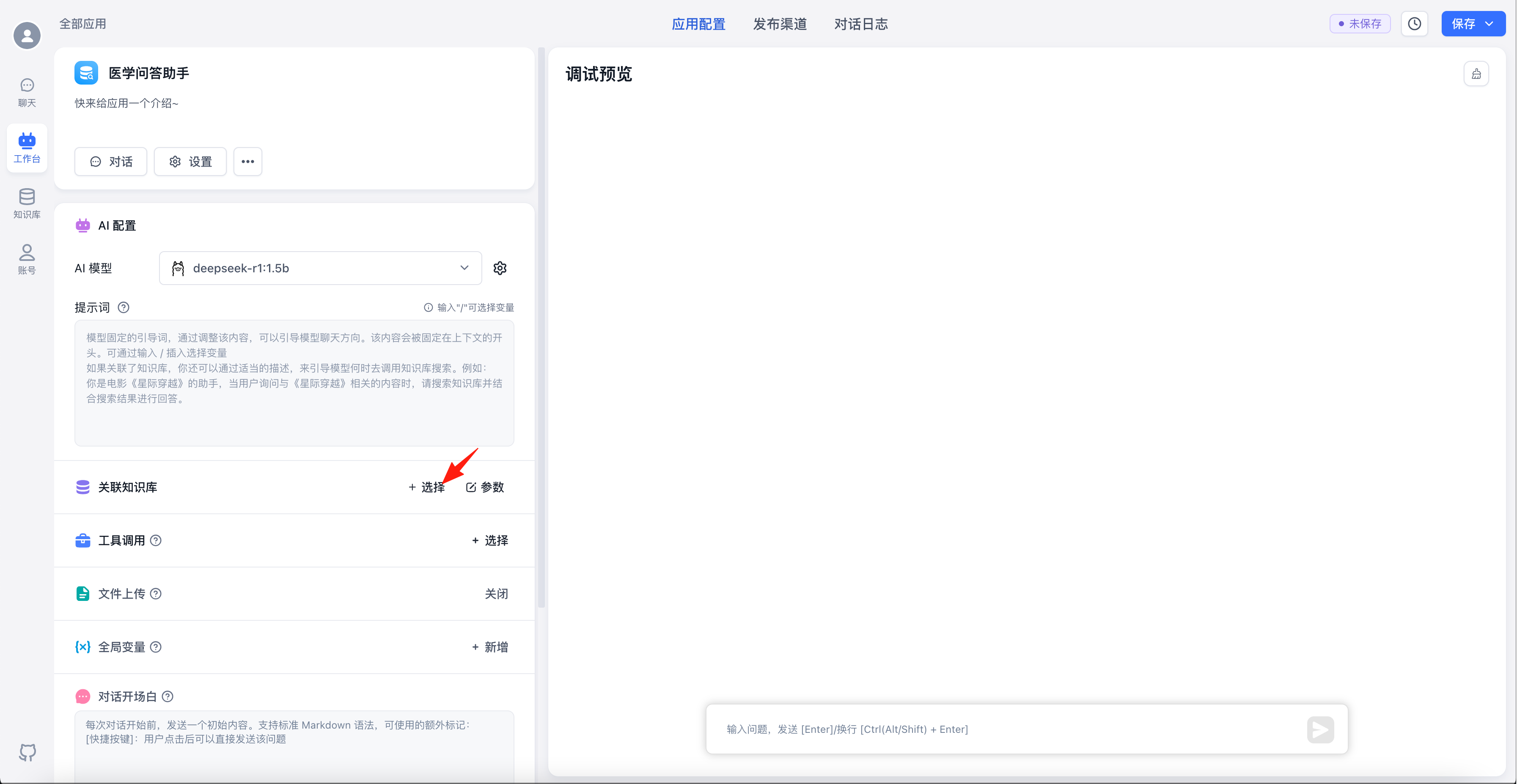
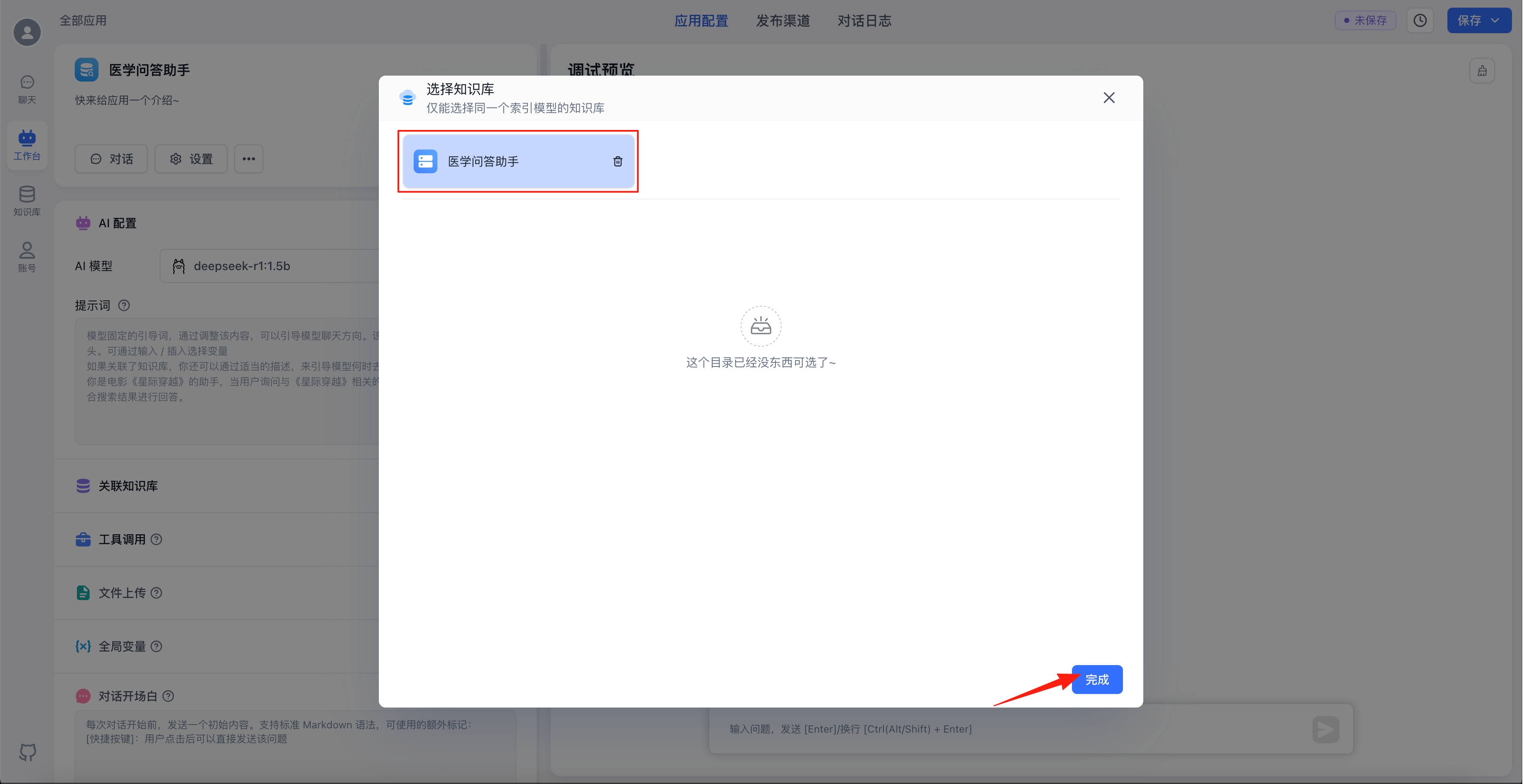
点击关联知识库右侧的“+选择”
选中刚刚创建的知识库,点击“完成”
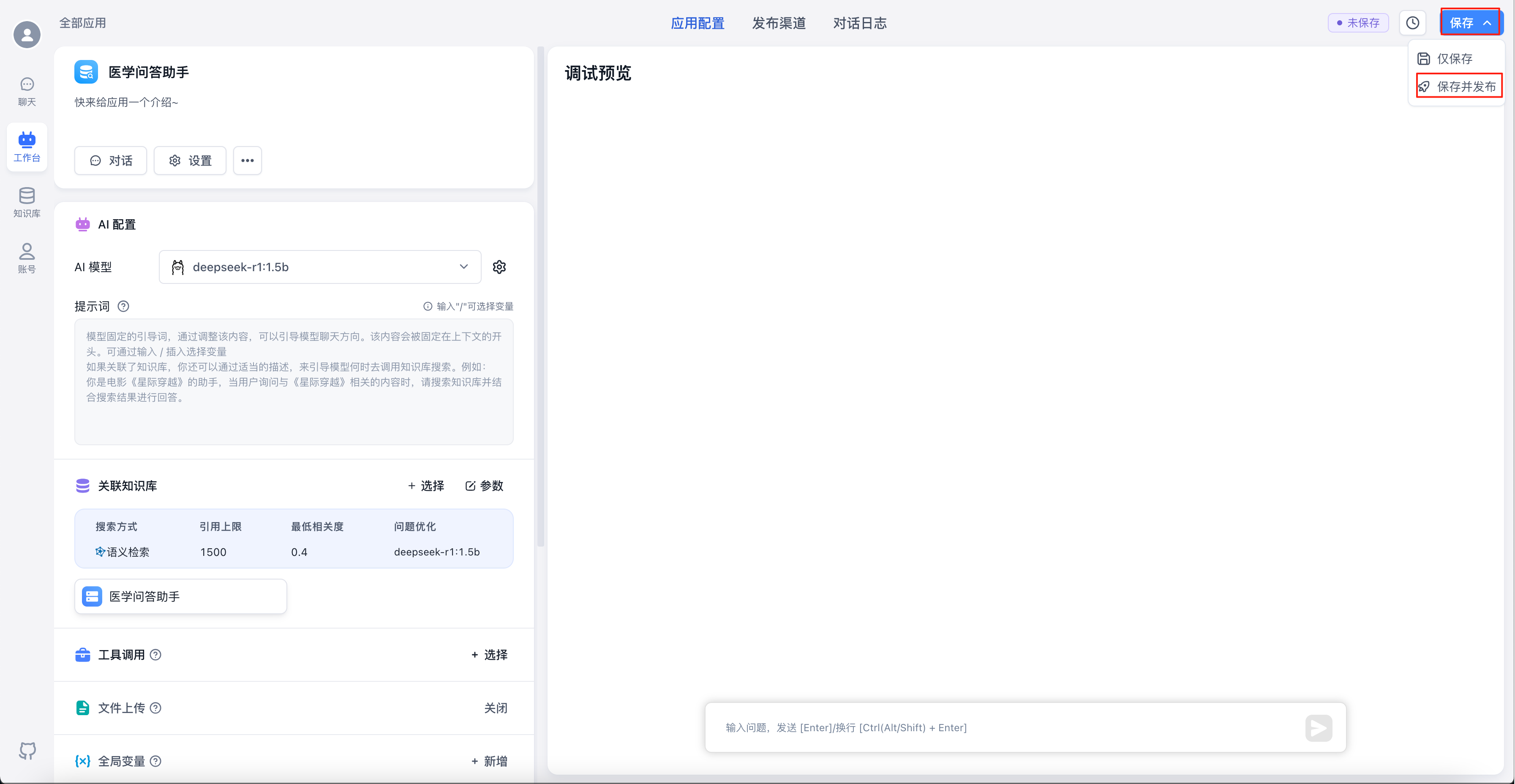
点击右上角的“保存”-“保存并发布”
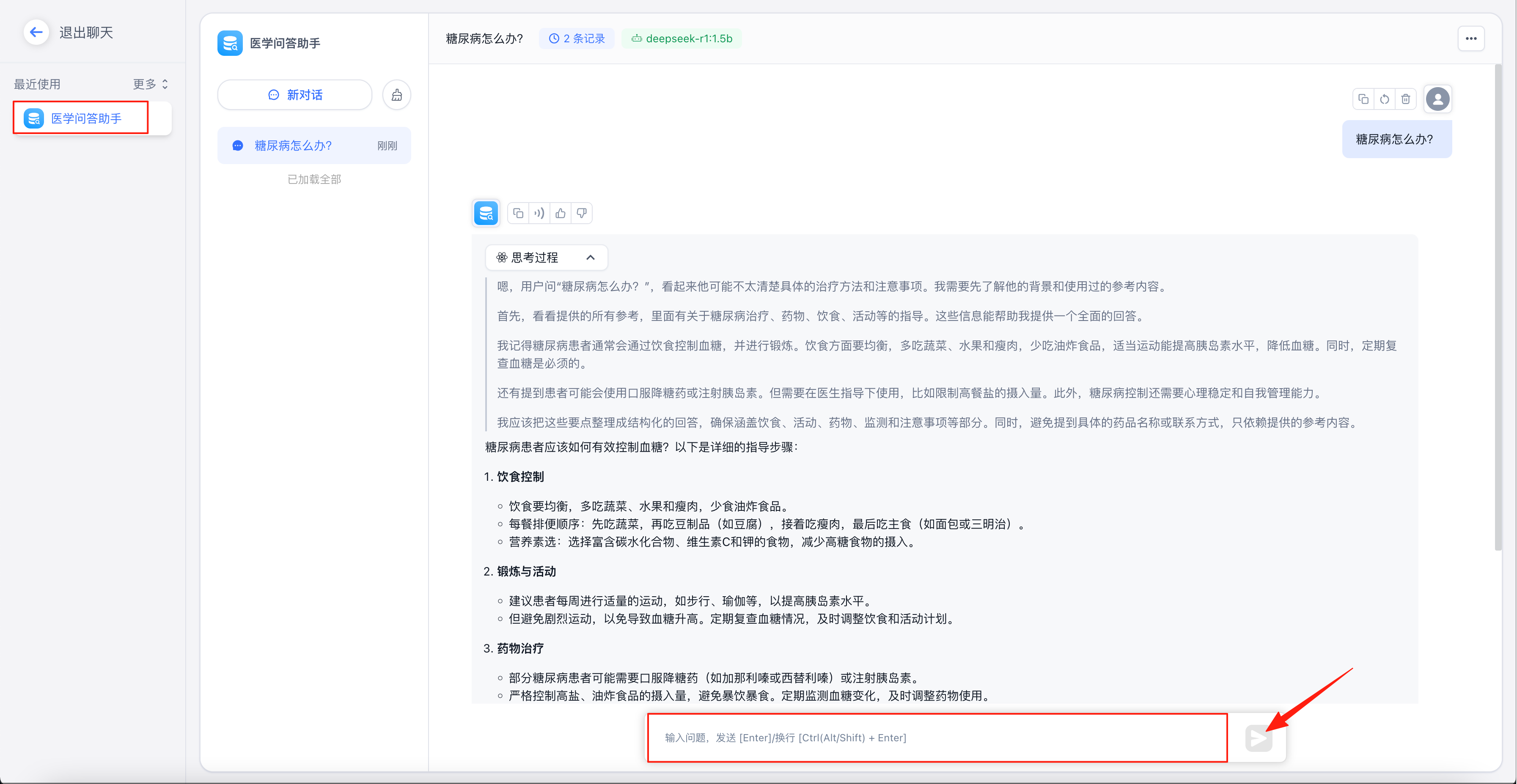
问答体验
选择“聊天”

左侧选中刚创建的问答助手,输入问题,点击发送即可。