Cephadm介绍 官方文档:https://docs.ceph.com/en/latest/cephadm/
cephadm用于部署和管理Ceph集群,它通过SSH将manager守护进程连接到主机来实现这一点。manager守护进程支持添加、删除和更新Ceph容器。cephadm不依赖外部配置工具,例如Ansible、Rook和Salt。
cephadm管理Ceph集群的整个生命周期。此生命周期从引导过程开始,cephadm在单个节点上创建一个小型Ceph集群。此集群由一个监视器(MON)和一个管理器(MGR)组成。然后,cephadm使用编排接口扩展集群,添加所有主机并提供所有Ceph守护进程和服务。此生命周期的管理可以通过Ceph命令行接口或仪表盘(Dashboard)执行。
说明 cephadm是Ceph v15.2.0(Octopus)中的新功能,不支持旧版本的Ceph。并且由于某些功能还在开发完善中,部署方式也会随着版本更新会有比较大的变化,建议多参考对应版本的官方文档
警告
cephadm正在积极开发中,兼容性与稳定性请关注官方说明
环境信息
主机名
配置
操作系统
IP地址
角色
磁盘(除系统盘)
ceph-mon01
2核4G
CentOS7.5/CentOS8.3
10.211.55.7
cephadm
100G * 3
ceph-mon02
2核4G
CentOS7.5/CentOS8.3
10.211.55.8
MON
100G * 3
ceph-mon03
2核4G
CentOS7.5/CentOS8.3
10.211.55.9
MON
100G * 3
环境要求
Python3
容器运行时,例如Docker、Podman
所有节点之间保持时间同步,使用chrony或NTP服务
用于调配存储设备的LVM2
初始化配置
说明
配置主机名 1 hostnamectl set-hostname <hostname>
关闭SELINUX 1 2 3 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config setenforce 0 reboot
关闭防火墙 1 2 systemctl stop firewalld systemctl disable firewalld
节点之间时间同步 server端 任选一台机器作为server端,如果环境可以访问互联网,可以不需要自己搭建server端,参考后面的client端部分设置所有节点与公网ntp时间服务器(例如time1.cloud.tencent.com)同步时间即可
CentOS7.x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 timedatectl set-timezone Asia/Shanghai yum install chrony ntpdate -y cp -a /etc/chrony.conf /etc/chrony.conf.bakcat > /etc/chrony.conf << EOF stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 allow 10.211.55.0/24 # 设置为实际环境客户端所属IP网段 smoothtime 400 0.01 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 local stratum 8 manual keyfile /etc/chrony.keys #initstepslew 10 client1 client3 client6 noclientlog logchange 0.5 logdir /var/log/chrony EOF systemctl restart chronyd.service systemctl enable chronyd.service systemctl status chronyd.service
CentOS8.x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 timedatectl set-timezone Asia/Shanghai dnf install chrony -y cp -a /etc/chrony.conf /etc/chrony.conf.bakcat > /etc/chrony.conf << EOF stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 allow 10.211.55.0/24 # 设置为实际环境客户端所属IP网段 smoothtime 400 0.01 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 local stratum 8 manual keyfile /etc/chrony.keys #initstepslew 10 client1 client3 client6 noclientlog logchange 0.5 logdir /var/log/chrony EOF systemctl restart chronyd.service systemctl enable chronyd.service systemctl status chronyd.service
client端
CentOS7.x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 timedatectl set-timezone Asia/Shanghai yum install chrony ntpdate -y cp -a /etc/chrony.conf /etc/chrony.conf.baksed -i "s%^server%#server%g" /etc/chrony.conf echo "server 10.211.55.7 iburst" >> /etc/chrony.conf ntpdate 10.211.55.7 systemctl restart chronyd.service systemctl enable chronyd.service systemctl status chronyd.service chronyc sources chronyc tracking
CentOS8.x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 timedatectl set-timezone Asia/Shanghai dnf install chrony -y cp -a /etc/chrony.conf /etc/chrony.conf.baksed -i "s%^pool%#pool%g" /etc/chrony.conf echo "pool 10.211.55.7 iburst" >> /etc/chrony.conf systemctl restart chronyd.service systemctl enable chronyd.service systemctl status chronyd.service chronyc sources chronyc tracking
配置Host解析 1 2 3 4 5 cat >> /etc/hosts << EOF 10.211.55.7 ceph-mon01 10.211.55.8 ceph-mon02 10.211.55.9 ceph-mon03 EOF
安装LVM2 安装Python3 安装Docker 配置docker-ce repository
1 2 3 4 5 6 7 8 9 yum install -y yum-utils \ device-mapper-persistent-data \ lvm2 yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo
说明
1 2 yum install wget -y wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
配置好Docker仓库后,运行如下命令安装最新版Docker
1 2 yum install docker-ce docker-ce-cli containerd.io -y
说明
1 2 3 4 5 yum list docker-ce --showduplicates | sort -r 例如:yum install docker-ce-18.09.9 docker-ce-cli-18.09.9 containerd.io -y
启动Docker并设置开机自启
1 2 3 systemctl start docker systemctl enable docker systemctl status docker
设置阿里云镜像加速器(可选)
1 2 3 4 5 6 7 8 9 10 mkdir -p /etc/dockercat > /etc/docker/daemon.json << EOF { "registry-mirrors": ["https://lerc8rqe.mirror.aliyuncs.com"] } EOF systemctl daemon-reload systemctl restart docker docker info
安装Cephadm
说明
使用curl获取cephadm脚本的最新版本。
1 2 cd /root/curl --remote-name --location https://github.com/ceph/ceph/raw/pacific/src/cephadm/cephadm
赋予cephadm脚本可执行权限
尽管cephadm脚本足以启动集群,但在主机上安装cephadm命令还是比较方便的。运行以下命令安装提供cephadm命令的软件包
1 2 3 4 5 6 7 8 9 ./cephadm add-repo --release octopus sed -i 's/download.ceph.com/mirrors.aliyun.com\/ceph/' /etc/yum.repos.d/ceph.repo sed -i 's/release.gpg/release.asc/' /etc/yum.repos.d/ceph.repo ./cephadm install
确认cephadm是否已加入PATH环境变量
返回如下内容表示添加成功
引导一个新集群
说明
说明 cephadm bootstrap命令,在Ceph集群的第一台主机上运行cephadm bootstrap命令会创建Ceph集群的第一个“监视器(MON)守护进程”,并且该监视器守护进程需要一个IP地址,因此需要知道该主机的IP地址。如果有多个网络和接口,请确保选择一个可供任何访问Ceph集群的主机访问的网络和接口。
说明 cephadm bootstrap的更多自定义配置可查阅关于CEPHADM引导的更多信息
运行ceph bootstrap命令
1 2 cephadm bootstrap --mon-ip 10.211.55.7
该命令执行以下操作:
在本地主机上为新集群创建监视器(MON)和管理器(MGR)守护进程
为Ceph集群生成新的SSH密钥,并将其添加到root用户的/root/.ssh/authorized_keys
将公钥的副本写入/etc/ceph/ceph.pub
将最小配置文件写入/etc/ceph/ceph.conf,与新集群通信需要此文件
将client.admin管理(特权)的密钥副本写入到/etc/ceph/ceph.client.admin.keyring
给引导主机添加_admin标签,默认情况下,具有此标签的主机也将获得/etc/ceph/ceph.conf和/etc/ceph/ceph.client.admin.keyring的副本
出现如下信息表示引导成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 Creating directory /etc/ceph for ceph.conf Verifying podman|docker is present... Verifying lvm2 is present... Verifying time synchronization is in place... Unit chronyd.service is enabled and running Repeating the final host check... podman|docker (/usr/bin/docker) is present systemctl is present lvcreate is present Unit chronyd.service is enabled and running Host looks OK Cluster fsid: 59428ec4-0f82-11ec-b6c6-001c423b10e7 Verifying IP 10.211.55.7 port 3300 ... Verifying IP 10.211.55.7 port 6789 ... Mon IP 10.211.55.7 is in CIDR network 10.211.55.0/24 Pulling container image docker.io/ceph/ceph:v15... Extracting ceph user uid/gid from container image... Creating initial keys... Creating initial monmap... Creating mon... Waiting for mon to start... Waiting for mon... mon is available Assimilating anything we can from ceph.conf... Generating new minimal ceph.conf... Restarting the monitor... Setting mon public_network... Creating mgr... Verifying port 9283 ... Wrote keyring to /etc/ceph/ceph.client.admin.keyring Wrote config to /etc/ceph/ceph.conf Waiting for mgr to start... Waiting for mgr... mgr not available, waiting (1/10)... mgr not available, waiting (2/10)... mgr not available, waiting (3/10)... mgr not available, waiting (4/10)... mgr is available Enabling cephadm module... Waiting for the mgr to restart... Waiting for Mgr epoch 5... Mgr epoch 5 is available Setting orchestrator backend to cephadm... Generating ssh key... Wrote public SSH key to to /etc/ceph/ceph.pub Adding key to root@localhost's authorized_keys... Adding host ceph-mon01... Deploying mon service with default placement... Deploying mgr service with default placement... Deploying crash service with default placement... Enabling mgr prometheus module... Deploying prometheus service with default placement... Deploying grafana service with default placement... Deploying node-exporter service with default placement... Deploying alertmanager service with default placement... Enabling the dashboard module... Waiting for the mgr to restart... Waiting for Mgr epoch 13... Mgr epoch 13 is available Generating a dashboard self-signed certificate... Creating initial admin user... Fetching dashboard port number... Ceph Dashboard is now available at: URL: https://ceph-mon01:8443/ User: admin Password: t0rpyr1kvh You can access the Ceph CLI with: sudo /usr/sbin/cephadm shell --fsid 59428ec4-0f82-11ec-b6c6-001c423b10e7 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring Please consider enabling telemetry to help improve Ceph: ceph telemetry on For more information see: https://docs.ceph.com/docs/master/mgr/telemetry/ Bootstrap complete.
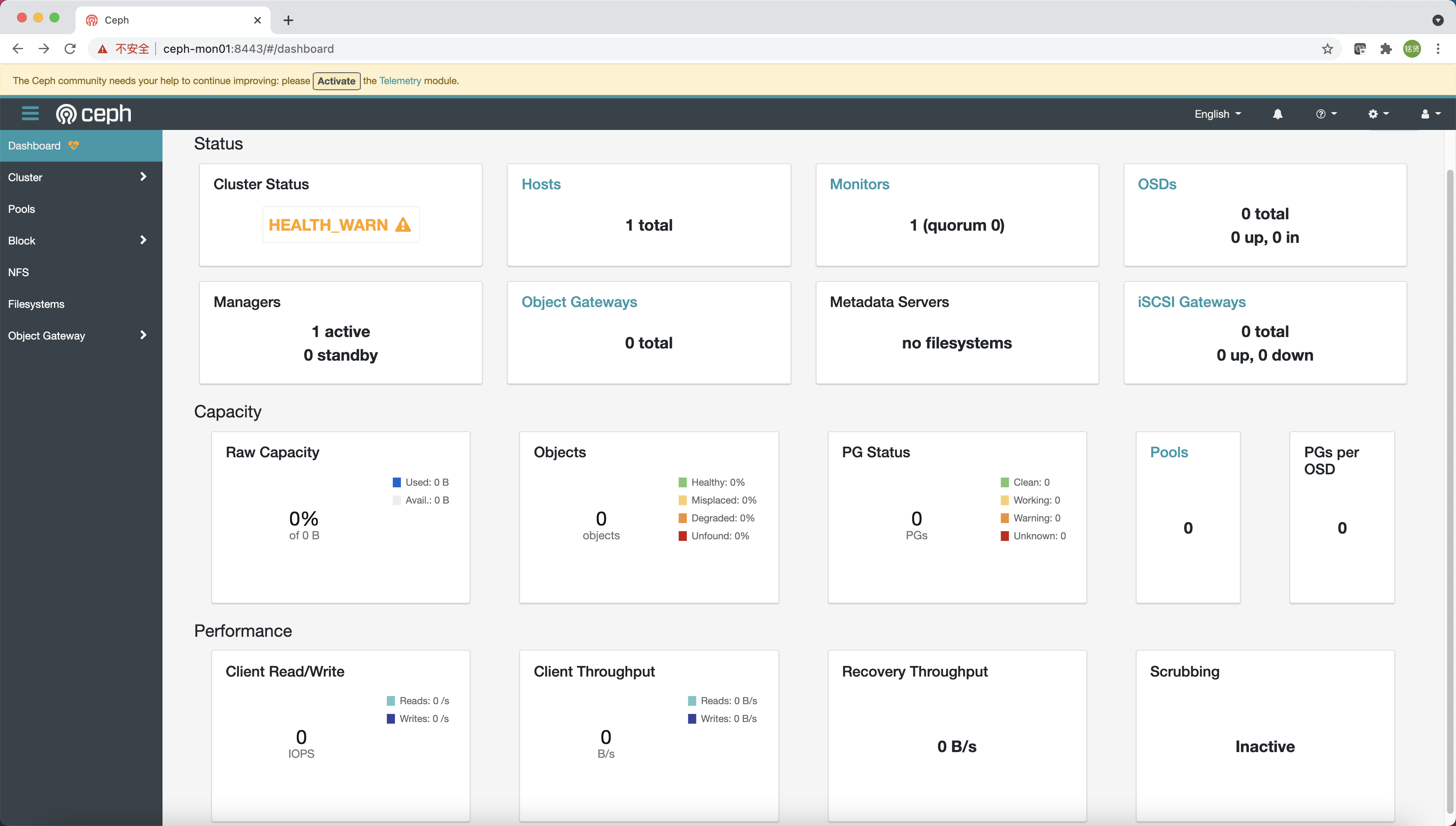
根据引导完成的提示信息使用浏览器访问Dashboard(https://ceph-mon01:8443/),修改密码后登录到Ceph Dashboard
说明
还有一个实时显示Ceph集群状态的Grafana展示页面(https://ceph-mon01:3000/)
查看当前配置文件
1 2 3 4 5 [root@ceph-mon01 ~] total 12 -rw------- 1 root root 63 Sep 7 10:24 ceph.client.admin.keyring -rw-r--r-- 1 root root 173 Sep 7 10:24 ceph.conf -rw-r--r-- 1 root root 595 Sep 7 10:24 ceph.pub
查看当前拉取的镜像及容器运行状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@ceph-mon01 ~] REPOSITORY TAG IMAGE ID CREATED SIZE ceph/ceph-grafana 6.7.4 557c83e11646 4 weeks ago 486MB ceph/ceph v15 2cf504fded39 3 months ago 1.03GB prom/prometheus v2.18.1 de242295e225 16 months ago 140MB prom/alertmanager v0.20.0 0881eb8f169f 21 months ago 52.1MB prom/node-exporter v0.18.1 e5a616e4b9cf 2 years ago 22.9MB [root@ceph-mon01 ~] CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 710c6f279ae1 prom/alertmanager:v0.20.0 "/bin/alertmanager -…" 25 minutes ago Up 25 minutes ceph-59428ec4-0f82-11ec-b6c6-001c423b10e7-alertmanager.ceph-mon01 d002498c898b ceph/ceph-grafana:6.7.4 "/bin/sh -c 'grafana…" 25 minutes ago Up 25 minutes ceph-59428ec4-0f82-11ec-b6c6-001c423b10e7-grafana.ceph-mon01 a6656d34fc7e prom/prometheus:v2.18.1 "/bin/prometheus --c…" 25 minutes ago Up 25 minutes ceph-59428ec4-0f82-11ec-b6c6-001c423b10e7-prometheus.ceph-mon01 a0707fb1c1ad prom/node-exporter:v0.18.1 "/bin/node_exporter …" 25 minutes ago Up 25 minutes ceph-59428ec4-0f82-11ec-b6c6-001c423b10e7-node-exporter.ceph-mon01 952af5aec621 ceph/ceph:v15 "/usr/bin/ceph-crash…" 28 minutes ago Up 28 minutes ceph-59428ec4-0f82-11ec-b6c6-001c423b10e7-crash.ceph-mon01 03b6e8181a1e ceph/ceph:v15 "/usr/bin/ceph-mgr -…" 29 minutes ago Up 29 minutes ceph-59428ec4-0f82-11ec-b6c6-001c423b10e7-mgr.ceph-mon01.tjkdnx dd688c5ca51a ceph/ceph:v15 "/usr/bin/ceph-mon -…" 29 minutes ago Up 29 minutes ceph-59428ec4-0f82-11ec-b6c6-001c423b10e7-mon.ceph-mon01
通过以上信息可知此时在引导节点上已经运行了以下组件:
mgr:mon:crash:prometheus:alertmanager:node-exporter:grafana:
启用Ceph命令
说明
默认情况下cephadm不会在主机上安装任何Ceph软件包,需运行cephadm shell命令在安装了所有Ceph软件包的容器中启动Bash Shell(运行exit可退出Shell),在此特定的Shell中运行Ceph相关命令
说明 /etc/ceph中找到ceph.conf配置文件和ceph.client.admin.keyring文件,则会将它们传递到容器环境中,以便Shell能够完全正常工作。但若在MON主机上执行时,cephadm shell将从MON容器查找配置,而不是使用默认配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@ceph-mon01 ~] Inferring fsid 59428ec4-0f82-11ec-b6c6-001c423b10e7 Inferring config /var/lib/ceph/59428ec4-0f82-11ec-b6c6-001c423b10e7/mon.ceph-mon01/config Using recent ceph image ceph/ceph@sha256:056637972a107df4096f10951e4216b21fcd8ae0b9fb4552e628d35df3f61139 [ceph: root@ceph-mon01 /] cluster: id : 59428ec4-0f82-11ec-b6c6-001c423b10e7 health: HEALTH_WARN OSD count 0 < osd_pool_default_size 3 services: mon: 1 daemons, quorum ceph-mon01 (age 65m) mgr: ceph-mon01.tjkdnx(active, since 64m) osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs:
为了方便访问,我们可以在主机上安装ceph-common软件包,该软件包包含所有Ceph命令,包括ceph、rbd、mount.ceph等
1 cephadm install ceph-common
验证可通过本机的Ceph命令连接到集群
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@ceph-mon01 ~] ceph version 15.2.14 (cd3bb7e87a2f62c1b862ff3fd8b1eec13391a5be) octopus (stable) [root@ceph-mon01 ~] cluster: id : 59428ec4-0f82-11ec-b6c6-001c423b10e7 health: HEALTH_WARN OSD count 0 < osd_pool_default_size 3 services: mon: 1 daemons, quorum ceph-mon01 (age 72m) mgr: ceph-mon01.tjkdnx(active, since 72m) osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs:
添加主机
说明
要列出当前与集群关联的主机,可运行如下命令:
安装集群公钥 通过ssh-copy-id命令配置集群的公共SSH公钥至其它所有Ceph节点
1 2 3 ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-mon02 ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-mon03
添加指定新节点 通过ceph orch host add命令添加新节点到Ceph集群中
1 2 3 ceph orch host add ceph-mon02 ceph orch host add ceph-mon03
说明
1 2 3 ceph orch host add ceph-mon02 10.211.55.8 --labels _admin ceph orch host add ceph-mon03 10.211.55.9 --labels _admin
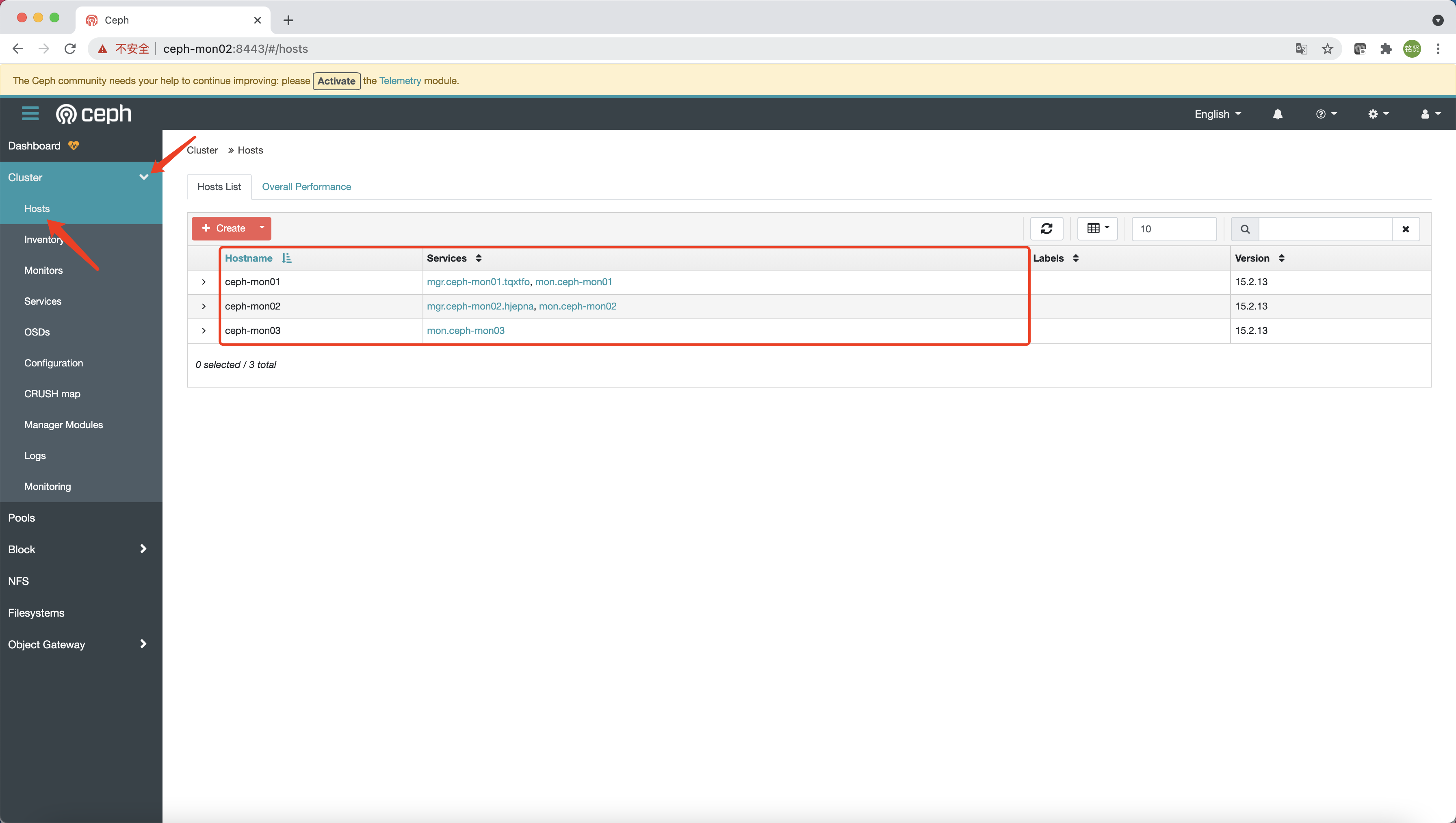
验证 查看Ceph纳管的所有节点
1 2 3 4 5 [root@ceph-mon01 ~] HOST ADDR LABELS STATUS ceph-mon01 ceph-mon01 ceph-mon02 ceph-mon02 ceph-mon03 ceph-mon03
说明 ceph -s)或Ceph的Dashboard页面查看添加情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@ceph-mon01 ~] cluster: id : 59428ec4-0f82-11ec-b6c6-001c423b10e7 health: HEALTH_WARN OSD count 0 < osd_pool_default_size 3 services: mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03 (age 3m) mgr: ceph-mon01.tjkdnx(active, since 3h), standbys: ceph-mon02.xsbwfv osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 0 B used, 0 B / 0 B avail pgs:
部署其他MON(可选)
说明
默认情况下,随着集群的增长,Ceph会自动部署MON守护程序,而随着集群的缩小,Ceph也会自动减少MON守护程序。此过程是自动的,就像在上节完成主机添加后,Ceph立即自动扩展MON到另外的两台节点(最多自动添加到5个MON)。如果要调整5个MON的默认值,可运行如下命令:
说明
如果要禁用MON的自动部署,可运行如下命令:
1 ceph orch apply mon --unmanaged
关于更多MON部署配置(例如指定子网部署)可参考官方文档MON Service章节
部署MGR(可选)
说明
添加节点后,Ceph会自动扩展MGR节点,可通过ceph orch ls mgr命令查看当前MGR数量
1 2 3 [root@ceph-mon01 ~] NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID mgr 2/2 13m ago 4h count:2 docker.io/ceph/ceph:v15 2cf504fded39
可以看到,默认会启动2个MGR,若要查看具体运行MGR的节点可通过如下ceph orch ps --daemon_type mgr命令
1 2 3 4 [root@ceph-mon01 ~] NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID mgr.ceph-mon01.tjkdnx ceph-mon01 running (5h) 2m ago 5h 15.2.13 docker.io/ceph/ceph:v15 2cf504fded39 03b6e8181a1e mgr.ceph-mon02.xsbwfv ceph-mon02 running (70m) 2m ago 70m 15.2.13 docker.io/ceph/ceph:v15 2cf504fded39 42a4c31b56ad
可以看到,MGR运行在ceph-mon01和ceph-mon02上,若想继续扩展MGR节点,可运行如下命令:
警告 官网DAEMON PLACEMENT
1 2 ceph orch apply mgr ceph-mon01,ceph-mon02,ceph-mon03
部署OSD
说明
列出设备 ceph-volume会不时扫描集群中的每个主机,以确定存在哪些设备以及这些设备是否可用做OSD。要查看cephadm发现的设备列表,可运行以下命令:
输出类似如下:
1 2 3 4 5 6 7 8 9 10 11 [root@ceph-mon01 ~] Hostname Path Type Serial Size Health Ident Fault Available ceph-mon01 /dev/sdb ssd 8Z4936Q8PZF4D1JASRYQ 107G Unknown N/A N/A Yes ceph-mon01 /dev/sdc ssd AM0DX7J0P1GMB0EQXPFX 107G Unknown N/A N/A Yes ceph-mon01 /dev/sdd ssd PGWTZ524HYN491KQVCQT 107G Unknown N/A N/A Yes ceph-mon02 /dev/sdb ssd AQZ2M4ZSSRX4DFE5RY5F 107G Unknown N/A N/A Yes ceph-mon02 /dev/sdc ssd BM5SC0FQRRG41E99GTHC 107G Unknown N/A N/A Yes ceph-mon02 /dev/sdd ssd AV9N08EQ9454QCTM96CE 107G Unknown N/A N/A Yes ceph-mon03 /dev/sdb ssd 3GM1QMR6F6P4DBQ549FS 107G Unknown N/A N/A Yes ceph-mon03 /dev/sdc ssd NHR9XHJBAD3M78YYAARC 107G Unknown N/A N/A Yes ceph-mon03 /dev/sdd ssd D859EG5FWB1MNCF2KFZV 107G Unknown N/A N/A Yes
说明 --wide选项提供与设备相关的所有详细信息,包括设备可能不适合用作OSD的任何原因
如果满足以下所有条件,则认为存储设备可用:
设备必须没有分区
设备不得具有任何LVM状态
设备必须没有被挂载
设备必须没有包含任何文件系统
设备不得包含Ceph BlueStore OSD
设备必须大于5GB
创建OSD 有几种方式可以创建新的OSD:
方式一(不推荐) 自动使用任何可用且未使用的存储设备
1 ceph orch apply osd --all-available-devices
运行上述命令后:
如果向集群中添加新硬盘,将自动用于创建新的OSD
如果删除OSD并清理LVM物理卷,将自动创建新的OSD
如果要禁用在可用设备上自动创建OSD,可使用非托管参数
1 ceph orch apply osd --all-available-devices --unmanaged=true
方式二(推荐) 从指定的主机的指定设备创建OSD
1 2 3 4 5 6 7 8 9 10 11 12 ceph orch daemon add osd ceph-mon01:/dev/sdb ceph orch daemon add osd ceph-mon01:/dev/sdc ceph orch daemon add osd ceph-mon01:/dev/sdd ceph orch daemon add osd ceph-mon02:/dev/sdb ceph orch daemon add osd ceph-mon02:/dev/sdc ceph orch daemon add osd ceph-mon02:/dev/sdd ceph orch daemon add osd ceph-mon03:/dev/sdb ceph orch daemon add osd ceph-mon03:/dev/sdc ceph orch daemon add osd ceph-mon03:/dev/sdd
方式三(推荐) 可以使用高级OSD服务规范 根据设备的属性对设备进行分类。这有助于更清楚地了解哪些设备可供消费。属性包括设备类型(SSD或HDD)、设备型号名称、大小以及设备所在的主机等
1 ceph orch apply -i spec.yml
检查OSD和集群状态 通过ceph -s确定OSD状态是否均处于up并in状态,集群状态是否为HEALTH_OK
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@ceph-mon01 ~] cluster: id : 59428ec4-0f82-11ec-b6c6-001c423b10e7 health: HEALTH_OK services: mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03 (age 5m) mgr: ceph-mon03.yrxrfd(active, since 5m), standbys: ceph-mon02.hjepna, ceph-mon01.tqxtfo osd: 9 osds: 9 up (since 2m), 9 in (since 2m) data: pools: 1 pools, 1 pgs objects: 0 objects, 0 B usage: 9.0 GiB used, 891 GiB / 900 GiB avail pgs: 1 active+clean
也可通过Dashboard查看OSD和集群状态
使用Ceph集群提供块存储服务
说明
确认默认pg_num和副本数
pg_num: 根据Total PGs = (#OSDs * 100) / pool size公式来决定pg_num(pgp_num应该设成和pg_num一样),所以9*100/3=300,官方建议取最接近的2的指数倍数,比如256。这是针对集群中所有pool的,每个pool的默认pg_num建议设置更小,比如32副本数: 默认副本数建议为3,最小副本数建议为2
配置默认pg_num和副本数 动态更新配置
1 2 3 4 ceph tell mon.\* injectargs '--osd_pool_default_size=3' ceph tell mon.\* injectargs '--osd_pool_default_min_size=2' ceph tell mon.\* injectargs '--osd_pool_default_pg_num=32' ceph tell mon.\* injectargs '--osd_pool_default_pgp_num=32'
创建块存储池 创建一个块存储池koenli
1 2 3 4 5 6 ceph osd pool create koenli 32 32 ceph osd pool application enable koenli rbd
创建完pool后再次查看集群状态,确认pgs均为active+clean状态,并且集群状态为HEALTH_OK
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@ceph-mon01 ~] cluster: id : 59428ec4-0f82-11ec-b6c6-001c423b10e7 health: HEALTH_OK services: mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03 (age 61m) mgr: ceph-mon03.yrxrfd(active, since 61m), standbys: ceph-mon01.tqxtfo, ceph-mon02.hjepna osd: 9 osds: 9 up (since 61m), 9 in (since 16h) data: pools: 2 pools, 33 pgs objects: 12 objects, 0 B usage: 9.0 GiB used, 891 GiB / 900 GiB avail pgs: 33 active+clean
创建块并映射到本地 创建一个10G的块
1 2 rbd create --size 10G disk01 --pool koenli
查看rbd
1 2 3 4 5 rbd ls koenli -l rbd info koenli/disk01
将rbd块映射到本地
查看映射,可见koenli/disk0已经映射到本地,相当于本地的一块硬盘/dev/rbd0,可对其进行分区、格式化、挂载等相关操作,此处不再赘述。
1 2 3 id pool namespace image snap device 0 koenli disk01 - /dev/rbd0
取消映射并删除块 1 2 3 4 5 rbd unmap koenli/disk01 rbd remove koenli/disk01
使用Ceph集群提供对象存储服务
说明
部署RGW Cephadm将radosgw部署为守护进程的集合,这些守护进程管理单个集群或多站点(multisite)中的特定realm和zone(有关realm和zone的更多信息可参见Multi-Site )
说明 client.rgw.<something>部分),那么radosgw守护进程将以默认设置启动(例如绑定到端口80)。
要部署一组radosgw守护进程,请运行以下命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 radosgw-admin realm create --rgw-realm=default-realm --default radosgw-admin zonegroup create --rgw-zonegroup=default-zonegroup --master --default radosgw-admin zone create --rgw-zonegroup=default-zonegroup --rgw-zone=default-zone --master --default radosgw-admin period update --rgw-realm=default-realm --commit ceph orch apply rgw default-realm default-zone --placement="3 ceph-mon01 ceph-mon02 ceph-mon03"
说明 svc_id,可参考如下。Pacific版本之后是否还有变化请参考官方文档
1 2 ceph orch apply rgw koenli-rgw default-realm default-zone --placement="3 ceph-mon01 ceph-mon02 ceph-mon03"
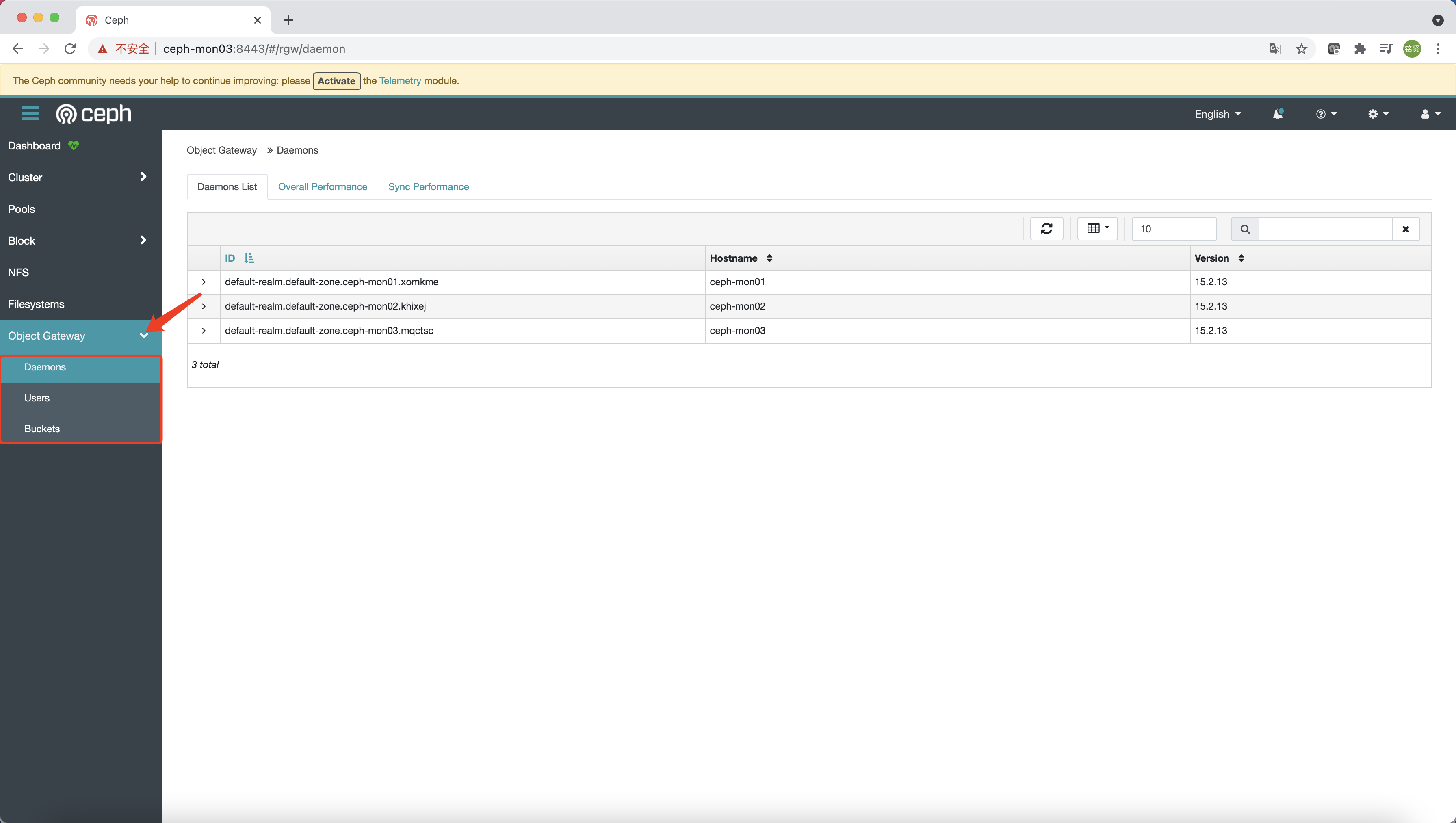
通过ceph -s确定RGW是否active,集群状态是否为HEALTH_OK
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@ceph-mon01 ~] cluster: id : 59428ec4-0f82-11ec-b6c6-001c423b10e7 health: HEALTH_OK services: mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03 (age 2h) mgr: ceph-mon03.yrxrfd(active, since 2h), standbys: ceph-mon01.tqxtfo, ceph-mon02.hjepna osd: 9 osds: 9 up (since 2h), 9 in (since 18h) rgw: 3 daemons active (default-realm.default-zone.ceph-mon01.xomkme, default-realm.default-zone.ceph-mon02.khixej, default-realm.default-zone.ceph-mon03.mqctsc) task status: data: pools: 6 pools, 153 pgs objects: 243 objects, 5.5 KiB usage: 9.0 GiB used, 891 GiB / 900 GiB avail pgs: 153 active+clean progress: PG autoscaler decreasing pool 6 PGs from 32 to 8 (0s) [............................]
说明 HEALTH_OK,不过下方的progress显示正在进行PG数量的调整,原因是Ceph在Nautilus版本中引入了PG的自动调整功能 ,待自动调整完成后即可。
配置Dashboard(可选)
说明
https://docs.ceph.com/en/octopus/mgr/dashboard/#enabling-the-object-gateway-management-frontend
由于RGW拥有自己的一套账号体系,所以为了能够使用Dashboard的对象存储网关管理功能,需要在RGW中创建一个Dashboard用的账号
1 2 radosgw-admin user create --uid=dashboard --display-name=dashboard --system
通过如下命令导出
1 2 3 4 radosgw-admin user info --uid=dashboard | grep access_key | awk -F '"' '{print $4}' > /root/rgw-dashboard-access-key radosgw-admin user info --uid=dashboard | grep secret_key | awk -F '"' '{print $4}' > /root/rgw-dashboard-secret-key
最后将相关凭证配置到Dashboard
1 2 3 4 ceph dashboard set-rgw-api-access-key -i /root/rgw-dashboard-access-key ceph dashboard set-rgw-api-secret-key -i /root/rgw-dashboard-secret-key
配置完成后即可在Dashboard上使用对象存储网关的管理功能
RGW高可用
说明 cephadm新增了一个实现RGW服务高可用的功能
ingress服务支持使用最少的一组配置为RGW服务创建高可用性端点(endpoint),orchestrator将部署和管理HAProxy和Keepalive的组合,以在虚拟IP上为RGW提供负载平衡服务。
说明
由上图可看到,有N台主机部署了ingress服务。每个主机都有一个HAProxy守护程序和一个Keepalived守护程序。一次只能在其中一台主机上自动配置虚拟IP。
每个Keepalived守护程序每隔几秒钟检查一次同一主机上的HAProxy守护程序是否有响应。Keepalived还将检查处于MASTER状态的Keepalived守护程序是否正常运行。如果处于MASTER状态的Keepalived守护程序或HAProxy没有响应,则在BACKUP模式下运行的其余Keepalived守护程序中的一个将被选举为MASTER,虚拟IP也将移动到该节点。
HAProxy就像负载平衡器一样,在所有可用的RGW守护进程之间分发所有RGW请求。
具体的部署请参考官方文档相关内容
使用Ceph集群提供文件存储服务
说明
使用CEPFS文件系统需要一个或多个MDS守护进程。
创建文件存储池 创建两个存储池,cephfs_metadata用于存文件系统元数据,cephfs_data用于存文件系统数据
1 2 3 4 5 6 7 8 ceph osd pool create cephfs_metadata 32 32 ceph osd pool create cephfs_data 32 32 ceph osd pool application enable cephfs_metadata cephfs ceph osd pool application enable cephfs_data cephfs
创建文件系统 1 2 ceph fs new koenlifs cephfs_metadata cephfs_data
部署MDS 1 2 ceph orch apply mds koenlifs --placement="3 ceph-mon01 ceph-mon02 ceph-mon03"
查看文件系统和MDS状态 1 2 3 4 5 name: koenlifs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] koenlifs:1 {0=ceph-mon01=up:active} 2 up:standby
验证挂载 在要挂载的节点上安装EPEL软件源并配置对应版本的Ceph软件源
说明
CentOS7.x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm -y CEPH_STABLE_RELEASE=octopus cat > /etc/yum.repos.d/ceph.repo << EOF [Ceph] name=Ceph packages for \$basearch baseurl=https://mirrors.aliyun.com/ceph/rpm-${CEPH_STABLE_RELEASE}/el7/\$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=https://mirrors.aliyun.com/ceph/rpm-${CEPH_STABLE_RELEASE}/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://mirrors.aliyun.com/ceph/rpm-${CEPH_STABLE_RELEASE}/el7/SRPMS/ enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc EOF
CentOS8.x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm -y CEPH_STABLE_RELEASE=pacific cat > /etc/yum.repos.d/ceph.repo << EOF [Ceph] name=Ceph \$basearch baseurl=https://mirrors.aliyun.com/ceph/rpm-${CEPH_STABLE_RELEASE}/el8/\$basearch enabled=1 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [Ceph-noarch] name=Ceph noarch baseurl=https://mirrors.aliyun.com/ceph/rpm-${CEPH_STABLE_RELEASE}/el8/noarch enabled=1 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc [Ceph-source] name=Ceph SRPMS baseurl=https://mirrors.aliyun.com/ceph/rpm-${CEPH_STABLE_RELEASE}/el8/SRPMS enabled=1 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc EOF
在要挂载的节点上安装ceph-fuse
1 yum install ceph-fuse -y
将引导节点/etc/ceph目录下的文件和/var/lib/ceph/{fsid}/mon.{hostname}/config文件拷贝到要挂载的节点上
说明
1 2 scp -r /etc/ceph/* <client_ip>:/etc/ceph/ scp -r /var/lib/ceph/{fsid}/mon.{hostname}/config <client_ip>:/etc/ceph/ceph.conf
使用ceph-fuse命令挂载
说明 ceph-fuse的使用说明可以参考官方文档
1 2 ceph-fuse -n client.admin -m 10.211.55.7:6789,10.211.55.8:6789,10.211.55.9:6789 /mnt/
说明 /etc/fstab中添加如下相关条目
1 2 none /mnt/ fuse.ceph ceph.id=admin,ceph.conf=/etc/ceph/ceph.conf,_netdev,defaults 0 0
卸载
说明 /etc/fstab中的对应挂载条目
部署NFS ganesha服务
说明
说明
说明
首先创建nfs-ganesha存储池
1 2 3 4 5 6 ceph osd pool create nfs-ganesha 32 32 ceph osd pool application enable nfs-ganesha nfs
然后通过cephadm部署NFS Ganesha守护进程(或一组守护进程)。NFS的配置存储在nfs-ganesha存储池中并且通过ceph nfs export ...命令或通过Dashboard仪表板管理服务暴露
说明
Octopus版本
1 2 ceph orch apply nfs nfs nfs-ganesha nfs-ns --placement="3 ceph-mon01 ceph-mon02 ceph-mon03"
Pacific版本
1 2 ceph orch apply nfs nfs --placement="3 ceph-mon01 ceph-mon02 ceph-mon03" nfs-ganesha nfs
检查NFS Ganesha守护进程状态
1 2 3 [root@ceph-mon01 ~] NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID nfs.nfs 3/3 20s ago 23s ceph-mon01;ceph-mon02;ceph-mon03;count:3 docker.io/ceph/ceph:v15 mix
说明
1 2 ceph dashboard set-ganesha-clusters-rados-pool-namespace nfs-ganesha/nfs-ns
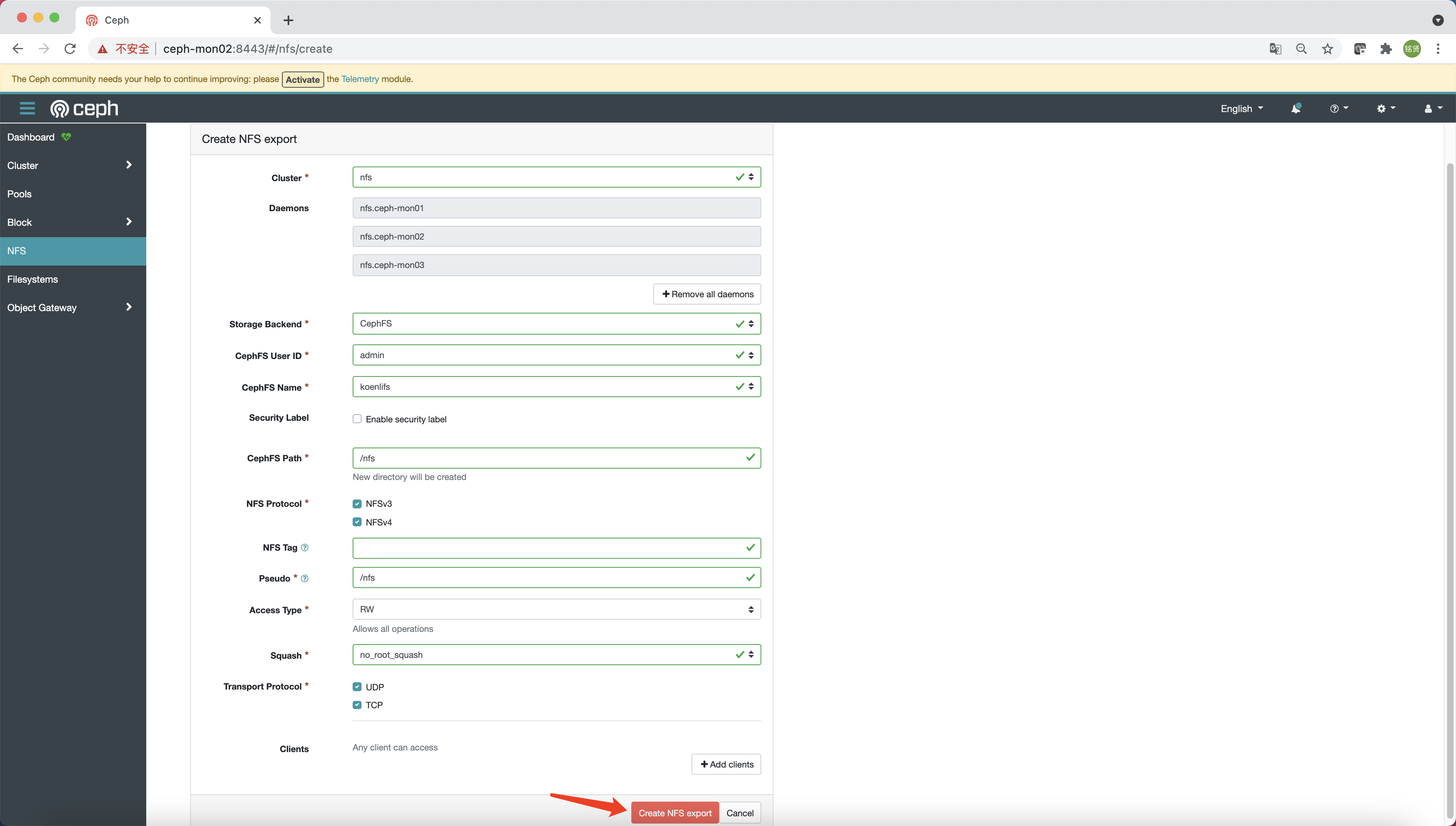
访问Dashboard,选择“NFS”,单击“Create”
参考下图填写相关配置信息,最后单击“Create NFS export”
说明 /nfs目录,则需先参考上面使用ceph-fuse命令挂载的步骤,在cephfs中创建nfs目录(目录名称与CephFS Path对应)后再次单击“Create NFS export”即可
在客户端节点验证NFS挂载
说明 <daemon_ip>与创建NFS export时选择的Daemons主机IP匹配;<path>与创建NFS export时指定的CephFS Path对应
1 2 3 4 5 6 yum install nfs-utils -y mount -t nfs <daemon_ip>:<path> /mnt/ umount /mnt
部署iSCSI服务
说明
创建iSCSI所需要的存储池
1 2 3 4 5 6 ceph osd pool create iscsi_pool 32 32 ceph osd pool application enable iscsi_pool iscsi
创建iSCSI的yaml文件
说明 官方文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 cat > /root/iscsi.yaml << EOF service_type: iscsi service_id: iscsi placement: hosts: - ceph-mon01 - ceph-mon02 - ceph-mon03 spec: pool: iscsi_pool trusted_ip_list: "10.211.55.7,10.211.55.8,10.211.55.9" api_user: admin api_password: admin api_secure: false EOF
部署iSCSI
1 ceph orch apply -i /root/iscsi.yaml
查看iSCSI service和daemon状态
1 2 3 4 5 6 7 8 9 [root@ceph-mon01 ~] NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID iscsi.iscsi 3/3 82s ago 11m ceph-mon01;ceph-mon02;ceph-mon03 docker.io/ceph/ceph:v15 2cf504fded39 [root@ceph-mon01 ~] NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID iscsi.iscsi.ceph-mon01.nrzxxd ceph-mon01 running (12m) 117s ago 12m 3.4 docker.io/ceph/ceph:v15 2cf504fded39 c08463f22484 iscsi.iscsi.ceph-mon02.wildwn ceph-mon02 running (11m) 114s ago 12m 3.4 docker.io/ceph/ceph:v15 2cf504fded39 fc66428f36c8 iscsi.iscsi.ceph-mon03.pafnwf ceph-mon03 running (12m) 117s ago 12m 3.4 docker.io/ceph/ceph:v15 2cf504fded39 f44058c79b34
查看Ceph Dashboard状态
如何剔除OSD 从集群中剔除OSD包括两个步骤:
从集群中撤出此OSD上所有的PG
从集群中卸载无PG的OSD
以下命令执行这两个步骤:
可以使用ceph orch osd rm status命令查询OSD操作的状态
Troubleshooting 无法rbd映射到本地
问题现象
将rbd映射到本地时出现如下错误信息:
1 2 3 4 rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable koenli/disk01 object-map fast-diff deep-flatten" . In some cases useful info is found in syslog - try "dmesg | tail" . rbd: map failed: (6) No such device or address
解决方法
因为CentOS7默认内核版本不支持Ceph的一些特性,需要手动禁用掉才能map成功
1 rbd feature disable koenli/disk01 object-map fast-diff deep-flatten
参考文档